RAID-guide: Forklaring, niveauer, fordele og ulemper
RAID-guide: Klar forklaring af niveauer, fordele og ulemper samt praktiske opsætningstips for bedre ydeevne, databeskyttelse og genopretning.
Indhold
· 1 Indledning
o 1.1 Forskellen mellem fysiske diske og logiske diske
o 1.2 Læsning og skrivning af data
o 1.3 Hvad er RAID?
o 1.4 Hvorfor bruge RAID?
o 1.5 Historie
· 2 Grundlæggende begreber, der anvendes i RAID-systemer
o 2.1 Caching
o 2.2 Spejling: Mere end én kopi af dataene
o 2.3 Striber: En del af dataene er på en anden disk
o 2.4 Fejlretning og fejl
o 2.5 Hot spares: Brug af flere diske end nødvendigt
o 2.6 Stripe-størrelse og chunk-størrelse: Fordeling af data på flere diske
o 2.7 Sammensætning af en disk: JBOD, sammenkædning eller spanning
o 2.8 Kloning af drev
o 2.9 Forskellige opsætninger
· 3 Grundlæggende: enkle RAID-niveauer
o 3.1 RAID-niveauer i almindelig brug
§ 3.1.1 RAID 0 "striping"
§ 3.1.2 RAID 1 "spejling"
§ 3.1.3 RAID 5 "striping med distribueret paritet"
§ 3.1.4 Billeder
o 3.2 RAID-niveauer, der anvendes mindre
§ 3.2.1 RAID 2
§ 3.2.2 RAID 3 "striping med dedikeret paritet"
§ 3.2.3 RAID 4 "striping med dedikeret paritet"
§ 3.2.4 RAID 6
§ 3.2.5 Billeder
o 3.3 Ikke-standard RAID-niveauer
§ 3.3.1 Dobbelt paritet / Diagonal paritet
§ 3.3.2 RAID-DP
§ 3.3.3.3 RAID 1.5
§ 3.3.4 RAID 5E, RAID 5EE og RAID 6E
§ 3.3.5 RAID 7
§ 3.3.6 Intel Matrix RAID
§ 3.3.7 Linux MD RAID-driver til MD
§ 3.3.8 RAID Z
§ 3.3.9 Billeder
· 4 Sammenføjning af RAID-niveauer
· 5 Oprettelse af et RAID
o 5.1 Software RAID
o 5.2 Hardware RAID
o 5.3 Hardware-assisteret RAID
· 6 Forskellige udtryk vedrørende hardwarefejl
o 6.1 Fejlprocent
o 6.2 Gennemsnitlig tid til datatab
o 6.3 Gennemsnitlig tid til genopretning
o 6.4 Uoprettelig bitfejlrate
· 7 Problemer med RAID
o 7.1 Tilføjelse af diske på et senere tidspunkt
o 7.2 Sammenhængende fejl
o 7.3 Atomicitet
o 7.4 Data, der ikke kan genfindes
o 7.5 Pålidelighed af skrivecache
o 7.6 Udstyrets kompatibilitet
· 8 Hvad RAID kan og ikke kan gøre
o 8.1 Hvad RAID kan gøre
o 8.2 Hvad RAID ikke kan gøre
· 9 Eksempel
· 10 referencer
· 11 Andre websteder
RAID er et akronym, der står for Redundant Array of Inexpensive Disks eller Redundant Array of Independent Disks. RAID er et begreb, der anvendes inden for computerbrug. Med RAID gøres flere harddiske til én logisk disk. Der er forskellige måder, hvorpå dette kan gøres. Hver af de metoder, hvor harddiskene sættes sammen, har nogle fordele og ulemper i forhold til at bruge diskene som enkelte diske, der er uafhængige af hinanden.
Hvorfor bruge RAID?
De vigtigste grunde til at bruge RAID er:
- For at beskytte mod tab af data ved at have redundans (mere end én kopi eller ved hjælp af paritet).
- For at øge lagerkapaciteten ved at kombinere flere mindre diske til ét stort logisk drev.
- For at øge ydeevnen — især læsehastigheden — ved at fordele data over flere drev.
- For at få større fleksibilitet, f.eks. mulighed for at udskifte eller tilføje diske, mens systemet kører (hot-swap / online expansion).
Det er ikke muligt at opnå alle disse mål fuldstændigt på samme tid — der er altid kompromiser mellem hastighed, kapacitet, omkostning og beskyttelse.
Fordele og begrænsninger
- Fordele: øget fejl-tolerance (afhænger af RAID-type), bedre læse-/skriveperformance i visse opsætninger, centraliseret lagerstyring.
- Begrænsninger: RAID beskytter ikke mod alle former for datatab (f.eks. utilsigtet sletning eller korruption). Genopbygning af et array efter diskfejl kan tage lang tid på store diske, og der kan opstå yderligere fejl under genopbygning.
- Nogle RAID-opsætninger bruger ældre eller inkompatible hardware/drivere, hvilket kan skabe problemer ved udskiftning af komponenter.
Kort historisk note
Konceptet RAID blev formaliseret i en indflydelsesrig artikel fra 1988. Siden da er teknologien blevet videreudviklet, og omkostningerne er faldet, så RAID i dag findes i både servermiljøer og forbrugerudstyr (f.eks. netværkstilsluttede lagringsenheder til musik og film).
Grundlæggende begreber
Her er de centrale begreber, som går igen i de fleste RAID-systemer:
- Spejling (mirroring): Samme data skrives til to eller flere diske (f.eks. RAID 1). Beskytter mod diskfejl, men halverer effektiv kapacitet ved 2-vejs spejling.
- Striping: Data opdeles i blokke ("stripes" eller "chunks") og spredes over flere diske. Giver øget ydeevne, men ingen redundans alene (f.eks. RAID 0).
- Paritet: En form for fejlinformation, som gemmes sammen med dataene, så man kan genskabe tabte data hvis en disk fejler (bruges i RAID 5, RAID 6 m.fl.).
- Hot spare: En ekstra disk i systemet, som automatisk kan erstatte en defekt disk og starte genopbygning uden manuel indsats.
- Caching: Hukommelse i controlleren eller systemet, som kan øge hastigheden. Vær opmærksom på, at skrivecache uden batteri eller ikke‑volatil cache kan medføre datatab ved strømsvigt.
- Stripe-størrelse / chunk-størrelse: Bestemmer hvor store blokke der skrives til hver disk før næste disk bruges. Valg påvirker ydeevne afhængigt af arbejdsbelastning (store sekventielle vs. små tilfældige I/O).
- JBOD (Just a Bunch Of Disks): Diskene ses hver for sig eller kædes sammen uden RAID-paritet/spejling.
De mest almindelige RAID-niveauer
Nedenfor er en kort og praktisk gennemgang af de hyppigst brugte niveauer:
RAID 0 — Striping
- Fordel: Meget bedre ydeevne og fuld pladsudnyttelse (kapacitet = sum af alle diske).
- Ulempe: Ingen redundans — hvis én disk fejler, går alle data tabt.
- Anvendelse: Midlertidige data, caches, eller arbejdsområder hvor ydeevne er vigtigere end sikkerhed.
RAID 1 — Spejling
- Fordel: Høj redundans — hver blok findes på mindst to diske. Hurtige læsninger (kan læse fra flere diske samtidig).
- Ulempe: Halveret effektiv kapacitet ved 2-vejs spejling.
- Anvendelse: Systemdisk til vigtige servere, databaser hvor sikkerhed er vigtigere end lagringskapacitet.
RAID 5 — Striping med distribueret paritet
- Fordel: Balanceret mellem kapacitet, ydeevne og redundans. Kan tåle én disks fejl uden tab af data.
- Ulempe: Skriveperformance kan være påvirket pga. paritetsberegning. Ved genopbygning (rebuild) er array sårbart; risiko for fejl ved store diske pga. uoprettelige læsefejl (URE'er).
- Anvendelse: Generel filserverbrug med moderat krav til både sikkerhed og kapacitet.
RAID 6 — Dobbelt paritet
- Fordel: Tåler to samtidige diskfejl. Mindre sårbar ved genopbygning på store diske.
- Ulempe: Mere kompleks paritetsberegning; lidt mindre kapacitet end RAID5 (kapacitet = N-2 diske).
- Anvendelse: Store arrays og miljøer med store diske, hvor sandsynligheden for en ekstra fejl under genopbygning er høj.
RAID 10 (1+0) — Spejlede striber
- Kombinerer fordelene ved RAID 1 og RAID 0: striping for ydeevne og spejling for redundans.
- Fordel: Høj ydeevne og høj fejl-tolerance afhængig af hvilke diske der fejler.
- Ulempe: Kræver mindst 4 diske og medfører overhead på 50 % kapacitetsmæssigt (ved 2-vejs spejling).
- Anvendelse: Databaser og applikationer med høje krav til både ydeevne og sikkerhed.
Andre og ikke-standard niveauer
Der findes mange variationer og proprietære løsninger som RAID 5E, RAID 5EE, RAID 6E, RAID-DP (Double Parity), RAID Z (ZFS), samt hardware-leverandørers egne varianter (f.eks. Intel Matrix RAID, RAID 7). Disse løser ofte specifikke behov som forbedret genopbygning, performanceoptimering eller avanceret fejlkorrektion.
Software RAID vs. Hardware RAID
- Software RAID: Håndteres af operativsystemet (f.eks. Linux MD/RAID). Fordele: fleksibilitet, omkostningseffektivt, kan migreres mellem hardware. Ulemper: CPU-belastning, kan være langsommere i visse scenarier.
- Hardware RAID: Bruger en dedikeret controller, ofte med egen cache og firmware. Fordele: mindre belastning af system-CPU, bedre skrivecache-muligheder. Ulemper: afhængighed af controller-driver og firmware; ved controllerfejl kan recovery blive vanskelig hvis controller ikke kan erstattes med identisk model.
- Hardware-assisteret RAID: Hybridløsninger hvor CPU hjælper med paritetsberegning, eller hvor en controller hjælper med I/O uden at være fuldstændig ansvarlig for logisk array.
Problemer og risici
- Genopbygningstid: Store diske betyder lange genopbygningstider; længere tid med nedsat redundans øger risikoen for yderligere fejl.
- Uoprettelig bitfejlrate (URE): Sandsynligheden for at en sektor ikke kan læses under en genopbygning. Ved store diske kan sandsynligheden for at støde på en URE under genopbygning blive kritisk for RAID5.
- Sammenhængende fejl: Fejl på grund af firmware, batch-fejl i diske fra samme producent, eller miljømæssige problemer (strøm, køling) kan medføre flere samtidige fejl.
- Skrivecache og atomicitet: Risiko for korruption hvis skrivecache ikke er beskyttet (f.eks. batteri eller ikke‑flygtig cache) og systemet mister strøm midt i en skriveoperation.
- Kompatibilitet: At flytte diske mellem forskellige controllers kan være problematisk, især med proprietære metadata.
Hvad RAID kan og ikke kan gøre
RAID kan:
- Øge tilgængelighed og modstandsdygtighed over for diskfejl (afhængigt af niveau).
- Forbedre læse- og/eller skriveydelse ved parallel adgang til flere diske.
- Centralisere lager styringen.
RAID kan ikke erstatte backup:
- RAID beskytter ikke mod menneskelige fejl (sletning), softwarefejl, virusangreb eller fysisk skade der påvirker alle kopier.
- RAID beskytter ikke automatisk mod korruption eller datarot — versionering og separate backups er stadig nødvendigt.
Praktiske anbefalinger
- Tag altid regelmæssige backups, og opbevar mindst én backup offsite eller i skyen.
- Overvej RAID 6 eller RAID10 for store diske og kritiske data. RAID5 kan være risikabelt med meget store kapaciteter.
- Brug enterprise-klasse diske i kritiske miljøer, og hold firmware opdateret.
- Brug hot-spares og overvågning for hurtig detektion og automatisk genopbygning.
- Sørg for, at controllerens skrivecache er batteri- eller ikke‑flygtigt beskyttet, hvis du anvender skrivecache.
- Test genopbygningsprocedurer og dokumentér, hvordan man gendanner arrayet ved hardwarefejl (særligt hvis proprietære controllere er i brug).
Eksempel
Et typisk eksempel: Et selskab kører en filserver med seks 4 TB diske i RAID6. Effektiv kapacitet er 4 × 4 TB = 16 TB (to diske bruges til paritet). Dette giver mulighed for, at to diske kan fejle uden tab. Hvis en disk går tabt, vil en hot-spare eller en ny disk automatisk påbegynde genopbygning. Under genopbygning kan I/O være langsommere, og der er stadig en risiko, hvis en tredje disk fejler før genopbygningen er fuldført — derfor overvågning og hurtig udskiftning er vigtigt.
Afsluttende bemærkninger
RAID er et kraftfuldt værktøj til at kombinere flere fysiske diske til ét logisk lager med valgfri redundans og/eller performanceforbedring. Valget af RAID-niveau bør baseres på krav til tilgængelighed, ydeevne og budget — og altid kombineres med et solidt backup-regime.
Virksomheder har brugt RAID-systemer til at lagre deres data, siden teknologien blev udviklet. Siden opdagelsen er omkostningerne ved at bygge et RAID-system faldet meget. Af denne grund har selv nogle computere og apparater, der bruges i hjemmet, nogle RAID-funktioner. Sådanne systemer kan for eksempel bruges til at gemme musik eller film.
Indledning
Forskellen mellem fysiske diske og logiske diske
En harddisk er en del af en computer. Normale harddiske bruger magnetisme til at lagre oplysninger. Når harddiske anvendes, er de tilgængelige for operativsystemet. I Microsoft Windows får hver harddisk et drevbogstav (startende med C:, A: eller B: er reserveret til diskettedrev). Unix- og Linux-lignende styresystemer har et enkelt rodfæstet mappetræ. Det betyder, at folk, der bruger computerne, nogle gange ikke ved, hvor oplysningerne er gemt (retfærdigvis skal det siges, at mange Windows-brugere heller ikke ved, hvor deres data er gemt).
Inden for databehandling kaldes harddiske (som er hardware og kan berøres) nogle gange fysiske drev eller fysiske diske. Det, som styresystemet viser brugeren, kaldes undertiden logiske diske. En fysisk disk kan opdeles i forskellige sektioner, der kaldes diskpartitioner. Normalt indeholder hver diskpartition ét filsystem. Operativsystemet vil vise hver partition som en logisk disk.
For brugeren vil derfor både opsætningen med mange fysiske diske og opsætningen med mange logiske diske se ens ud. Brugeren kan ikke afgøre, om en "logisk disk" er det samme som en fysisk disk, eller om den blot er en del af disken. Storage Area Networks (SAN'er) ændrer dette synspunkt fuldstændigt. Det eneste, der er synligt i et SAN, er et antal logiske diske.
Læsning og skrivning af data
I computeren er data organiseret i form af bits og bytes. I de fleste systemer består en byte af 8 bits. Computerhukommelse bruger elektricitet til at lagre data, mens harddiske bruger magnetisme. Når data skrives på en disk, omdannes det elektriske signal derfor til et magnetisk signal. Når data læses fra disken, sker konverteringen i den anden retning: Et elektrisk signal dannes ud fra polariteten af et magnetfelt.
Hvad er RAID?
Et RAID-array samler to eller flere harddiske, så de udgør en logisk disk. Der er forskellige grunde til, at dette gøres. De mest almindelige er:
- Stopper tab af data, når en eller flere diske i arrayet svigter.
- Få hurtigere dataoverførsler.
- Få mulighed for at skifte diske, mens systemet kører.
- Sammenføjning af flere diske for at få større lagerkapacitet; nogle gange bruges der mange billige diske i stedet for en dyrere disk.
RAID udføres ved hjælp af særlig hardware eller software på computeren. De sammenkoblede harddiske vil så se ud som én harddisk for brugeren. De fleste RAID-niveauer øger redundansen. Det betyder, at de lagrer dataene oftere, eller at de lagrer oplysninger om, hvordan dataene kan rekonstrueres. Dette gør det muligt for et antal diske at fejle, uden at dataene går tabt. Når den defekte disk udskiftes, kopieres eller genopbygges de data, som den skulle indeholde, fra de andre diske i systemet. Dette kan tage lang tid. Den tid, det tager, afhænger af forskellige faktorer, f.eks. arrayets størrelse.
Hvorfor bruge RAID?
En af grundene til, at mange virksomheder bruger RAID, er, at dataene i arrayet simpelthen kan bruges. De, der bruger dataene, behøver slet ikke at være klar over, at de bruger RAID. Når der er opstået en fejl, og arrayet er ved at blive genoprettet, vil adgangen til dataene være langsommere. Adgang til dataene i dette tidsrum vil også forsinke genoprettelsesprocessen, men det er stadig meget hurtigere end slet ikke at kunne arbejde med dataene. Afhængigt af RAID-niveauet er det dog muligt, at diskene ikke fejler, mens den nye disk forberedes til brug. Hvis en disk svigter på det tidspunkt, vil alle data i arrayet gå tabt.
De forskellige måder at sammenføje diske på kaldes RAID-niveauer. Et større tal for niveauet er ikke nødvendigvis bedre. De forskellige RAID-niveauer har forskellige formål. Nogle RAID-niveauer kræver særlige diske og særlige controllere.
Historie
I 1978 fremsatte en mand ved navn Norman Ken Ouchi, der arbejdede hos IBM, et forslag, der beskrev planerne for det, der senere skulle blive til RAID 5. Planerne beskrev også noget, der lignede RAID 1, samt beskyttelsen af en del af RAID 4.
Ansatte på Berkeley-universitetet var med til at planlægge forskningen i 1987. De forsøgte at gøre det muligt for RAID-teknologien at genkende to harddiske i stedet for én. De fandt ud af, at når RAID-teknologien havde to harddiske, havde den meget bedre lagerplads end med kun én harddisk. Den gik dog meget oftere ned.
I 1988 blev de forskellige RAID-typer (1 til 5) beskrevet af David Patterson, Garth Gibson og Randy Katz i deres artikel "A Case for Redundant Arrays of Inexpensive Disks (RAID)". Denne artikel var den første, der kaldte den nye teknologi for RAID, og navnet blev officielt.


Grundlæggende begreber, der anvendes i RAID-systemer
RAID anvender nogle få grundlæggende idéer, som blev beskrevet i artiklen "RAID: High-Performance, Reliable Secondary Storage" af Peter Chen m.fl. fra 1994.
Caching
Caching er en teknologi, som også kan anvendes i RAID-systemer. Der findes forskellige former for caches, der anvendes i RAID-systemer:
- Operativsystem
- RAID-controller
- Enterprise disk array
I moderne systemer vises en skriveanmodning som udført, når dataene er blevet skrevet til cachen. Dette betyder ikke, at dataene er blevet skrevet til disken. Anmodninger fra cachen behandles ikke nødvendigvis i samme rækkefølge, som de blev skrevet til cachen. Dette gør det muligt, at nogle data ikke er blevet skrevet til den pågældende disk, hvis systemet fejler. Af denne grund har mange systemer en cache, der er understøttet af et batteri.
Spejling: Mere end én kopi af dataene
Når vi taler om et spejl, er det en meget enkel idé. I stedet for at dataene kun er ét sted, er der flere kopier af dataene. Disse kopier befinder sig normalt på forskellige harddiske (eller diskpartitioner). Hvis der er to kopier, kan den ene af dem fejle, uden at dataene påvirkes (da de stadig er på den anden kopi). Spejling kan også give et løft ved læsning af data. De vil altid blive hentet fra den hurtigste disk, der reagerer. Det er dog langsommere at skrive data, fordi alle diske skal opdateres.
Striber: En del af dataene er på en anden disk
Ved striping opdeles dataene i forskellige dele. Disse dele ender så på forskellige diske (eller diskpartitioner). Det betyder, at det går hurtigere at skrive data, da det kan ske parallelt. Dette betyder ikke, at der ikke vil være fejl, da hver datablok kun findes på én disk.
Fejlkorrektion og fejl
Det er muligt at beregne forskellige former for checksumme. Nogle metoder til beregning af kontrolsummer gør det muligt at finde en fejl. De fleste RAID-niveauer, der anvender redundans, kan gøre dette. Nogle metoder er vanskeligere at udføre, men de gør det muligt ikke blot at opdage fejlen, men også at rette den.
Hot spares: Brug af flere diske end nødvendigt
Mange af de måder, hvorpå RAID understøtter noget, kaldes en hot spare. En hot spare er en tom disk, som ikke bruges i normal drift. Når en disk fejler, kan data kopieres direkte over på den hot spare-disk. På den måde skal den defekte disk erstattes af en ny tom disk for at blive hot spare-disk.
Stripe-størrelse og chunk-størrelse: Spredning af data på flere diske
RAID fungerer ved at sprede dataene over flere diske. To af de udtryk, der ofte anvendes i denne sammenhæng, er stripe size og chunk size.
Chunkstørrelsen er den mindste datablok, der skrives til en enkelt disk i arrayet. Strimlestørrelsen er størrelsen af en datablok, der spredes over alle diske. På den måde vil der med fire diske og en stripe-størrelse på 64 kilobyte (kB) blive skrevet 16 kB til hver disk. Størrelsen af en blok i dette eksempel er derfor 16 kB. Hvis stripe-størrelsen gøres større, vil det betyde en hurtigere dataoverførselshastighed, men også en større maksimal latenstid. I dette tilfælde er dette den tid, der er nødvendig for at få en blok data.
Sammensætning af en disk: JBOD, sammenkædning eller spanning
Mange controllere (og også software) kan sætte diske sammen på følgende måde: De tager den første disk, indtil den slutter, så tager de den anden og så videre. På den måde ser flere mindre diske ud som en større disk. Dette er ikke rigtig RAID, da der ikke er nogen redundans. Desuden kan spanning kombinere diske, hvor RAID 0 ikke kan gøre noget. Generelt kaldes dette bare en flok diske (JBOD).
Dette er som en fjern slægtning til RAID, fordi det logiske drev består af forskellige fysiske drev. Sammenkædning bruges nogle gange til at lave flere små drev om til et større nyttigt drev. Dette kan ikke gøres med RAID 0. F.eks. kan JBOD kombinere 3 GB, 15 GB, 5,5 GB og 12 GB-drev til et logisk drev på 35,5 GB, som ofte er mere nyttigt end drevene alene.
I diagrammet til højre er dataene sammenkædet fra slutningen af disk 0 (blok A63) til begyndelsen af disk 1 (blok A64); fra slutningen af disk 1 (blok A91) til begyndelsen af disk 2 (blok A92). Hvis der blev anvendt RAID 0, ville disk 0 og disk 2 blive afkortet til 28 blokke, størrelsen af den mindste disk i arrayet (disk 1), hvilket giver en samlet størrelse på 84 blokke.
Nogle RAID-controllere bruger JBOD til at tale om at arbejde på drev uden RAID-funktioner. Hvert drev vises separat i operativsystemet. Denne JBOD er ikke det samme som sammenkædning.
Mange Linux-systemer bruger udtrykkene "lineær tilstand" eller "append-tilstand". Implementeringen i Mac OS X 10.4 - kaldet "Concatenated Disk Set" - efterlader ikke brugeren med brugbare data på de resterende drev, hvis et drev svigter i et concatenated disk set, selv om diskene ellers fungerer som beskrevet ovenfor.
Sammenkædning er en af anvendelsesmulighederne for Logical Volume Manager i Linux. Den kan bruges til at oprette virtuelle drev.
Klon af drev
De fleste moderne harddiske har en standard, der kaldes S.M.A.R.T. (Self-Monitoring, Analysis and Reporting Technology). SMART gør det muligt at overvåge visse ting på en harddisk. Visse controllere gør det muligt at udskifte en enkelt harddisk, selv før den svigter, f.eks. fordi S.M.A.R.T. eller en anden disktest rapporterer for mange fejl, der kan rettes. For at gøre dette kopierer controlleren alle data til en hot spare-disk. Herefter kan disken udskiftes med en anden disk (som blot bliver den nye hot spare).
Forskellige opsætninger
Opsætningen af diskene, og hvordan de anvender ovenstående teknikker, påvirker systemets ydeevne og pålidelighed. Når der anvendes flere diske, er der større sandsynlighed for, at en af diskene fejler. På grund af dette skal der bygges mekanismer, der kan finde og rette fejl. Dette gør hele systemet mere pålideligt, da det er i stand til at overleve og reparere fejlen.

Grundlæggende: enkle RAID-niveauer
RAID-niveauer i almindelig brug
RAID 0 "striping"
RAID 0 er ikke rigtig RAID, fordi det ikke er redundant. Med RAID 0 sættes diskene simpelthen sammen til en stor disk. Dette kaldes "striping". Når en disk går i stykker, går hele arrayet i stykker. Derfor bruges RAID 0 sjældent til vigtige data, men læsning og skrivning af data fra disken kan være hurtigere med striping, fordi hver disk læser en del af filen på samme tid.
Med RAID 0 placeres diskblokke, der kommer efter hinanden, normalt på forskellige diske. Derfor skal alle diske, der anvendes af en RAID 0, have samme størrelse.
RAID 0 bruges ofte til Swapspace på Linux- eller Unix-lignende operativsystemer.
RAID 1 "spejling"
Med RAID 1 sættes to diske sammen. Begge indeholder de samme data, og den ene "spejler" den anden. Dette er en nem og hurtig konfiguration, uanset om den er implementeret med en hardwarecontroller eller ved hjælp af software.
RAID 5 "striping med distribueret paritet"
RAID-niveau 5 er det, der sandsynligvis bruges mest. Der skal mindst tre harddiske til for at opbygge et RAID 5-lagringsarray. Hver datablok vil blive gemt tre forskellige steder. To af disse steder vil blokken blive gemt som den er, mens det tredje sted vil gemme en kontrolsum. Denne checksumme er et specialtilfælde af en Reed-Solomon-kode, som kun anvender bitvis addition. Normalt beregnes den ved hjælp af XOR-metoden. Da denne metode er symmetrisk, kan en tabt datablok genopbygges ud fra den anden datablok og checksummen. For hver blok vil en anden disk indeholde paritetsblokken, som indeholder checksummen. Dette gøres for at øge redundansen. Enhver disk kan fejle. Samlet set vil der være én disk, der indeholder checksummene, så den samlede anvendelige kapacitet vil være den for alle diske undtagen én. Størrelsen af den resulterende logiske disk vil være størrelsen af alle diske tilsammen, bortset fra den ene disk, der indeholder paritetsoplysninger.
Dette er naturligvis langsommere end RAID-niveau 1, da alle diske skal læses ved hver skrivning for at beregne og opdatere paritetsoplysningerne. RAID 5's læseydelse er næsten lige så god som RAID 0 for det samme antal diske. Bortset fra paritetsblokkene følger fordelingen af data på diskene det samme mønster som i RAID 0. Grunden til, at RAID 5 er lidt langsommere, er, at diskene skal springe over paritetsblokkene.
En RAID 5 med en defekt disk vil fortsat fungere. Den er i degraderet tilstand. En degraderet RAID 5 kan være meget langsom. Af denne grund tilføjes der ofte en ekstra disk. Denne kaldes hot spare disk. Hvis en disk svigter, kan dataene genopbygges direkte på den ekstra disk. RAID 5 kan også ret nemt laves i software.
Primært på grund af ydelsesproblemer med fejlslagne RAID 5 arrays har nogle databaseeksperter dannet en gruppe kaldet BAARF - Battle Against Any Raid Five.
Hvis systemet fejler, mens der er aktive skrivninger, kan pariteten i en stribe blive inkonsistent med dataene. Hvis dette ikke repareres, inden en disk eller blok går ned, kan der opstå datatab. En forkert paritet vil blive brugt til at rekonstruere den manglende blok i den pågældende stribe. Dette problem er undertiden kendt som "skrivehullet". Batteribaserede caches og lignende teknikker anvendes almindeligvis for at mindske risikoen for, at dette sker.
Billeder
· 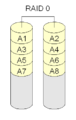
RAID 0 placerer simpelthen de forskellige blokke på forskellige diske. Der er ingen redundans.
· 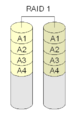
Med Raid 1 findes hver blok på begge diske
· 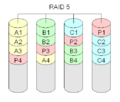
RAID 5 beregner særlige kontrolsummer for dataene. Både blokkene med checksummen og blokkene med dataene fordeles på alle diskene.
RAID-niveauer anvendes mindre
RAID 2
Dette blev brugt med meget store computere. Der er brug for særligt dyre diske og en særlig controller for at bruge RAID Level 2. Dataene fordeles på bit-niveau (alle andre niveauer anvender handlinger på byte-niveau). Der foretages særlige beregninger. Data opdeles i statiske sekvenser af bits. 8 databits og 2 paritetsbits sættes sammen. Derefter beregnes en Hamming-kode. Fragmenterne af Hamming-koden fordeles derefter på de forskellige diske.
RAID 2 er det eneste RAID-niveau, der kan reparere fejl, mens de andre RAID-niveauer kun kan registrere dem. Når de finder ud af, at de nødvendige oplysninger ikke giver mening, vil de simpelthen genopbygge dem. Dette gøres med beregninger ved hjælp af oplysninger på de andre diske. Hvis disse oplysninger mangler eller er forkerte, kan de ikke gøre meget. Da RAID 2 anvender Hamming-koder, kan den finde ud af, hvilken del af oplysningerne der er forkerte, og kun rette den del.
RAID 2 kræver mindst 10 diske for at fungere. På grund af kompleksiteten og behovet for meget dyrt og specielt hardware anvendes RAID 2 ikke længere særlig meget.
RAID 3 "striping med dedikeret paritet"
Raid Level 3 er meget lig RAID Level 0. Der tilføjes en ekstra disk til lagring af paritetsoplysninger. Dette sker ved bitvis addition af værdien af en blok på de andre diske. Paritetsoplysningerne gemmes på en separat (dedikeret) disk. Dette er ikke godt, for hvis paritetsdisken går ned, går paritetsoplysningerne tabt.
RAID-niveau 3 udføres normalt med mindst 3 diske. En opsætning med to diske er identisk med en RAID Level 0.
RAID 4 "striping med dedikeret paritet"
Dette svarer meget til RAID 3, bortset fra at paritetsoplysningerne beregnes over større blokke og ikke over enkelte bytes. Dette svarer til RAID 5. Der skal mindst tre diske til et RAID 4-array.
RAID 6
RAID-niveau 6 var ikke et oprindeligt RAID-niveau. Det tilføjer en ekstra paritetsblok til et RAID 5-array. Det kræver mindst fire diske (to diske for kapaciteten og to diske for redundans). RAID 5 kan ses som et specialtilfælde af en Reed-Solomon-kode. RAID 5 er dog et særtilfælde, idet den kun har brug for addition i Galois-feltet GF(2). Dette er let at gøre med XOR'er. RAID 6 udvider disse beregninger. Det er ikke længere et specialtilfælde, og alle beregningerne skal udføres. Med RAID 6 anvendes en ekstra checksum (kaldet polynomium), som regel af GF (28). Med denne fremgangsmåde er det muligt at beskytte mod et vilkårligt antal defekte diske. RAID 6 er for det tilfælde, hvor der anvendes to checksummene til at beskytte mod tab af to diske.
Ligesom med RAID 5 er paritet og data på forskellige diske for hver blok. De to paritetsblokke er også placeret på forskellige diske.
Der er forskellige måder at lave RAID 6 på. De er forskellige med hensyn til deres skriveydelse, og hvor mange beregninger der er nødvendige. At kunne foretage hurtigere skrivninger betyder normalt, at der er behov for flere beregninger.
RAID 6 er langsommere end RAID 5, men det gør det muligt for RAID at fortsætte, selv om to diske er defekte. RAID 6 er ved at blive populært, fordi det gør det muligt at genopbygge et array efter en fejl på en enkelt disk, selv om en af de resterende diske har en eller flere dårlige sektorer.
Billeder
· 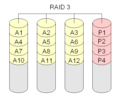
RAID 3 er meget lig RAID-niveau 0. Der tilføjes en ekstra disk, som indeholder en kontrolsum for hver datablok.
· 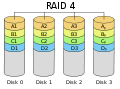
RAID 4 svarer til RAID-niveau 3, men beregner paritet over større blokke af data
· 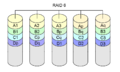
RAID 6 ligner RAID 5, men beregner to forskellige kontrolsummer. Dette gør det muligt for to diske at fejle uden tab af data.
Ikke-standardiserede RAID-niveauer
Dobbelt paritet / Diagonal paritet
RAID 6 bruger to paritetsblokke. Disse beregnes på en særlig måde over et polynomium. Ved dobbelt paritets-RAID (også kaldet diagonal paritets-RAID) anvendes et andet polynomium for hver af disse paritetsblokke. For nylig har den brancheorganisation, der har defineret RAID, sagt, at dobbelt paritets-RAID er en anden form for RAID 6.
RAID-DP
RAID-DP er en anden måde at have dobbelt paritet på.
RAID 1.5
RAID 1.5 (ikke at forveksle med RAID 15, som er anderledes) er en proprietær RAID-implementering. Ligesom RAID 1 bruger den kun to diske, men den udfører både striping og mirroring (svarende til RAID 10). De fleste ting foregår i hardware.
RAID 5E, RAID 5EE og RAID 6E
RAID 5E, RAID 5EE og RAID 6E (med tilføjelsen E for Enhanced) henviser generelt til forskellige typer af RAID 5 eller RAID 6 med en hot spare. Ved disse implementeringer er hot spare-drevet ikke et fysisk drev. Den findes snarere i form af ledig plads på diskene. Dette øger ydeevnen, men det betyder, at en hot spare-disk ikke kan deles mellem forskellige arrays. Ordningen blev indført af IBM ServeRAID omkring 2001.
RAID 7
Dette er en proprietær implementering. Den tilføjer caching til et RAID 3- eller RAID 4-array.
Intel Matrix RAID
Nogle Intel-hovedkort har RAID-chip, der har denne funktion. Den bruger to eller tre diske og partitionerer dem derefter ligeligt for at danne en kombination af RAID 0-, RAID 1-, RAID 5- eller RAID 1+0-niveauer.
Linux MD RAID-driver til MD
Dette er navnet på den driver, der gør det muligt at lave software-RAID med Linux. Ud over de normale RAID-niveauer 0-6 har den også en RAID 10-implementering. Siden Kernel 2.6.9 er RAID 10 et enkelt niveau. Implementeringen har nogle ikke-standardiserede funktioner.
RAID Z
Sun har implementeret et filsystem kaldet ZFS. Dette filsystem er optimeret til håndtering af store datamængder. Det omfatter en logisk volumenhåndtering. Det indeholder også en funktion kaldet RAID-Z. Det undgår det problem, der kaldes RAID 5 write hole, fordi det har en copy-on-write-politik: Den overskriver ikke dataene direkte, men skriver nye data på et nyt sted på disken. Når skrivningen er lykkedes, slettes de gamle data. Den undgår behovet for read-modify-write-operationer for små skrivninger, fordi den kun skriver hele striber. Små blokke spejles i stedet for at paritetsbeskyttes, hvilket er muligt, fordi filsystemet kender den måde, hvorpå lageret er organiseret. Det kan derfor tildele ekstra plads, hvis det er nødvendigt. Der findes også RAID-Z2, som anvender to former for paritet for at opnå resultater svarende til RAID 6: evnen til at overleve op til to drevfejl uden at miste data.
Billeder
· 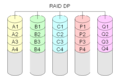
Diagram over en RAID DP (Double Parity)-opsætning.
· 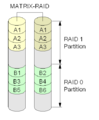
En Matrix RAID-opsætning.
Sammenføjning af RAID-niveauer
Med RAID kan forskellige diske sættes sammen til en logisk disk.Brugeren vil kun se den logiske disk. Hvert af de ovennævnte RAID-niveauer har gode og dårlige sider. Men RAID kan også fungere med logiske diske. På den måde kan et af de ovennævnte RAID-niveauer anvendes med et sæt logiske diske. Mange mennesker noterer det ved at skrive tallene sammen. Nogle gange skriver de et "+" eller et "&" imellem. Almindelige kombinationer (ved brug af to niveauer) er følgende:
- RAID 0+1: To eller flere RAID 0-arrays kombineres til et RAID 1-array; dette kaldes en Mirror of stripes
- RAID 1+0: Samme som RAID 0+1, men RAID-niveauerne er omvendt; Stripe of Mirrors. Dette gør diskfejl sjældnere end RAID 0+1 ovenfor.
- RAID 5+0: Stripe flere RAID 5'er med en RAID 0. En disk i hver RAID 5 kan fejle, men gør denne RAID 5 til det eneste fejlpunkt; hvis en anden disk i dette array fejler, vil alle data i arrayet gå tabt.
- RAID 5+1: Spejle et sæt RAID 5: I en situation, hvor RAID'en består af seks diske, kan tre af dem fejle (uden at data går tabt).
- RAID 6+0: Stripe flere RAID 6 arrays over et RAID 0; to diske i hvert RAID 6 kan fejle uden tab af data.
Med seks diske på 300 GB hver, en samlet kapacitet på 1,8 TB, er det muligt at lave en RAID 5 med 1,5 TB brugbar plads. I dette array kan en disk fejle uden tab af data. Med RAID 50 reduceres pladsen til 1,2 TB, men en disk i hver RAID 5 kan fejle, og der er desuden en mærkbar stigning i ydeevnen. RAID 51 reducerer den anvendelige størrelse til 900 GB, men tillader, at alle tre diske kan fejle.
· 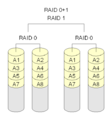
RAID 0+1: Flere RAID 0-arrays kombineres med et RAID 1
· 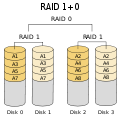
RAID 1+0: Mere robust end RAID 0+1; understøtter fejl på flere drev, så længe ingen af de to drev, der udgør et spejl, fejler.
· 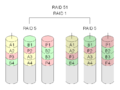
RAID 5+1: Alle tre drev kan fejle uden tab af data.
Oprettelse af et RAID
Der er forskellige måder at lave et RAID på. Det kan enten gøres med software eller med hardware.
Software RAID
Et RAID kan oprettes med software på to forskellige måder. I tilfælde af software-RAID er diskene forbundet som normale harddiske. Det er computeren, der får RAID'en til at fungere. Det betyder, at CPU'en for hver adgang også skal foretage beregningerne for RAID'en. Beregningerne for RAID 0 eller RAID 1 er enkle. Beregningerne for RAID 5, RAID 6 eller et af de kombinerede RAID-niveauer kan imidlertid være et stort arbejde. I et software-RAID kan det være vanskeligt at starte automatisk op fra et array, der er mislykkedes. Endelig afhænger den måde, som RAID udføres på i software, af det anvendte operativsystem; det er generelt ikke muligt at genopbygge et software-RAID-array med et andet operativsystem. Operativsystemer bruger normalt harddiskpartitioner i stedet for hele harddiske til at lave RAID-matricer.
Hardware RAID
En RAID kan også laves med hardware. I dette tilfælde anvendes en særlig diskcontroller; dette controller-kort skjuler det faktum, at det udfører RAID, for operativsystemet og brugeren. Beregningerne af checksum-informationer og andre RAID-relaterede beregninger foretages på en særlig mikrochip i denne controller. Dette gør RAID uafhængigt af operativsystemet. Operativsystemet vil ikke se RAID'en, men en enkelt disk. Forskellige producenter anvender RAID på forskellige måder. Det betyder, at et RAID, der er opbygget med en hardware-RAID-controller, ikke kan genopbygges af en anden RAID-controller fra en anden producent. Hardware-RAID-controllere er ofte dyre at købe.
Hardware-assisteret RAID
Dette er en blanding af hardware-RAID og software-RAID. Hardware-assisteret RAID bruger en særlig controllerchip (ligesom hardware-RAID), men denne chip kan ikke udføre mange operationer. Den er kun aktiv, når systemet startes; så snart operativsystemet er fuldt indlæst, er denne konfiguration som software-RAID. Nogle bundkort har RAID-funktioner for de tilsluttede diske; oftest udføres disse RAID-funktioner som hardware-assisteret RAID. Det betyder, at der er behov for særlig software for at kunne bruge disse RAID-funktioner og for at kunne genoprette en defekt disk.
Forskellige udtryk i forbindelse med hardwarefejl
Der er forskellige udtryk, der anvendes, når man taler om hardwarefejl:
Fejlprocent
Fejlfrekvensen er, hvor ofte et system fejler. Den gennemsnitlige tid til fejl (MTTF) eller den gennemsnitlige tid mellem fejl (MTBF) for et RAID-system er den samme som for dets komponenter. Et RAID-system kan jo ikke beskytte mod fejl på de enkelte harddiske. De mere komplicerede RAID-typer (alt andet end "striping" eller "concatenation") kan dog hjælpe med at holde dataene intakte, selv om en enkelt harddisk fejler.
Gennemsnitlig tid til datatab
Den gennemsnitlige tid til datatab (MTTDL) angiver den gennemsnitlige tid, der går, før der sker et datatab i et givet array. Den gennemsnitlige tid til datatab for et givet RAID kan være højere eller lavere end for dets harddiske. Dette afhænger af den anvendte RAID-type.
Gennemsnitlig tid til genopretning
Arrays, der har redundans, kan genoprette nogle fejl. Den gennemsnitlige tid til genopretning viser, hvor lang tid det tager, før et fejlslagent array er tilbage i normal tilstand. Hertil kommer både tiden til at udskifte en defekt diskmekanisme og tiden til at genopbygge arrayet igen (dvs. replikere data for at sikre redundans).
Uoprettelig bitfejlrate
UBE-raten (unrecoverable bit error rate) angiver, hvor længe et diskdrev ikke kan gendanne data efter brug af CRC-koder (cyclic redundancy check) og flere gentagelser.
Problemer med RAID
Der er også visse problemer med idéerne eller teknologien bag RAID:
Tilføjelse af diske på et senere tidspunkt
Visse RAID-niveauer gør det muligt at udvide arrayet ved blot at tilføje harddiske på et senere tidspunkt. Oplysninger som f.eks. paritetsblokke er ofte spredt på flere diske. Tilføjelse af en disk til arrayet betyder, at en reorganisering bliver nødvendig. En sådan reorganisering svarer til en genopbygning af arrayet, og det kan tage lang tid. Når dette er gjort, er den ekstra plads måske ikke tilgængelig endnu, fordi både filsystemet på arrayet og operativsystemet skal have besked om det. Nogle filsystemer understøtter ikke at blive vokset, efter at de er blevet oprettet. I så fald skal der tages backup af alle dataene, arrayet skal oprettes igen med det nye layout, og dataene skal gendannes på det.
En anden mulighed for at tilføje lagerplads er at oprette et nyt array og lade en logisk volumemanager håndtere situationen. Dette gør det muligt at udvide næsten alle RAID-systemer, selv RAID1 (som i sig selv er begrænset til to diske).
Sammenhængende fejl
Fejlkorrektionsmekanismen i RAID antager, at fejl på drev er uafhængige. Det er muligt at beregne, hvor ofte et udstyr kan fejle, og at arrangere arrayet således, at datatab er meget usandsynligt.
I praksis blev drevene dog ofte købt sammen. De har nogenlunde samme alder og er blevet brugt på samme måde (kaldet slitage). Mange drev svigter på grund af mekaniske problemer. Jo ældre et drev er, jo mere slidte er dets mekaniske dele. Mekaniske dele, der er gamle, er mere tilbøjelige til at gå i stykker end yngre dele. Det betyder, at fejl i drev ikke længere er statistisk uafhængige. I praksis er der en chance for, at en anden disk også går i stykker, inden den første disk er blevet genoprettet. Det betyder, at datatab i praksis kan forekomme med en betydelig hastighed.
Atomicitet
Et andet problem, der også opstår med RAID-systemer, er, at programmerne forventer det, der kaldes atomicitet: Enten bliver alle data skrevet, eller også bliver ingen data skrevet. Skrivning af data kaldes en transaktion.
I RAID-arrays skrives de nye data normalt på det sted, hvor de gamle data var. Dette er blevet kendt som opdatering på stedet. Jim Gray, en databaseforsker, skrev en artikel i 1981, hvor han beskrev dette problem.
Meget få lagringssystemer tillader atomisk skrivesemantik. Når et objekt skrives til disken, vil en RAID-lagerenhed normalt skrive alle kopier af objektet parallelt. Meget ofte er der kun én processor, der er ansvarlig for at skrive dataene. I så fald vil skrivningerne af data til de forskellige drev overlappe hinanden. Dette kaldes overlappende skrivning eller forskudt skrivning. En fejl, der opstår under skriveprocessen, kan derfor efterlade de redundante kopier i forskellige tilstande. Hvad værre er, kan den efterlade kopierne i hverken den gamle eller den nye tilstand. Logning er imidlertid afhængig af, at de oprindelige data enten er i den gamle eller den nye tilstand. Dette gør det muligt at foretage en backing out af den logiske ændring, men kun få lagringssystemer tilbyder en atomisk skrivesemantik på en RAID-disk.
Brug af en batteribaseret skrivecache kan løse dette problem, men kun i tilfælde af strømsvigt.
Transaktionsunderstøttelse findes ikke i alle hardware-RAID-controllere. Derfor indeholder mange operativsystemer den for at beskytte mod tab af data under en afbrudt skrivning. Novell Netware indeholdt fra og med version 3.x et system til sporing af transaktioner. Microsoft indførte transaktionssporing via journalfunktionen i NTFS. NetApp WAFL-filsystemet løser det ved aldrig at opdatere dataene på stedet, ligesom ZFS gør det.
Data, der ikke kan genoprettes
Nogle sektorer på en harddisk kan være blevet ulæselige på grund af en fejl. Nogle RAID-implementeringer kan håndtere denne situation ved at flytte dataene til et andet sted og markere sektoren på disken som dårlig. Dette sker ca. 1 bit ud af 1015 på diskdrev i virksomhedsklassen og 1 bit ud af 1014 på almindelige diskdrev. Diskkapaciteten stiger støt og roligt. Dette kan betyde, at et RAID nogle gange ikke kan genopbygges, fordi en sådan fejl findes, når arrayet genopbygges efter en diskfejl. Visse teknologier såsom RAID 6 forsøger at løse dette problem, men de lider under en meget høj skrivebøde, dvs. at det bliver meget langsomt at skrive data.
Pålidelighed af skrivecache
Disksystemet kan kvittere for skriveoperationen, så snart dataene er i cachen. Det behøver ikke at vente, indtil dataene er blevet skrevet fysisk. En strømafbrydelse kan imidlertid betyde et betydeligt datatab af data, der står i kø i en sådan cache.
Med hardware-RAID kan der bruges et batteri til at beskytte denne cache. Dette løser ofte problemet. Når strømmen svigter, kan controlleren afslutte skrivningen af cachen, når strømmen er tilbage. Denne løsning kan dog stadig fejle: batteriet kan være slidt op, strømmen kan have været slukket for længe, diskene kan være flyttet til en anden controller, selve controlleren kan fejle. Visse systemer kan foretage periodiske batterikontroller, men disse bruger selve batteriet og efterlader det i en tilstand, hvor det ikke er fuldt opladet.
Udstyrets kompatibilitet
Diskformaterne på forskellige RAID-controllere er ikke nødvendigvis kompatible. Derfor er det muligvis ikke muligt at læse et RAID-array på forskellig hardware. Derfor kan en fejl i hardwaren uden for disken kræve brug af identisk hardware eller en sikkerhedskopi for at gendanne dataene.
Hvad RAID kan og ikke kan gøre
Denne vejledning er hentet fra en tråd i et RAID-relateret forum. Dette blev gjort for at hjælpe med at påpege fordelene og ulemperne ved at vælge RAID. Den er rettet mod folk, der ønsker at vælge RAID for enten at øge ydelsen eller redundans. Den indeholder links til andre tråde i det pågældende forum, der indeholder brugergenererede anekdotiske anmeldelser af deres RAID-erfaringer.
Hvad RAID kan gøre
- RAID kan beskytte oppetiden. RAID-niveauerne 1, 0+1/10, 5 og 6 (og deres varianter som f.eks. 50 og 51) kompenserer for en mekanisk harddiskfejl. Selv efter at disken er gået i stykker, kan dataene på arrayet stadig bruges. I stedet for en tidskrævende gendannelse fra bånd, DVD eller andre langsomme sikkerhedskopieringsmedier gør RAID det muligt at gendanne data til en erstatningsdisk fra de andre medlemmer af arrayet. Under denne gendannelsesproces er de tilgængelige for brugere i en forringet tilstand. Dette er meget vigtigt for virksomheder, da nedetid hurtigt fører til tabt indtjeningsevne. For private brugere kan det beskytte oppetiden for store medieopbevaringsarrays, som ville kræve tidskrævende gendannelse fra snesevis af dvd'er eller en hel del bånd i tilfælde af en disk, der svigter, og som ikke er beskyttet af redundans.
- RAID kan øge ydeevnen i visse applikationer. RAID-niveau 0, 5 og 6 anvender alle striping. Dette gør det muligt for flere spindler at øge overførselshastigheden for lineære overførsler. Programmer af arbejdsstationstypen arbejder ofte med store filer. De har stor gavn af disk striping. Eksempler på sådanne applikationer er dem, der bruger video- eller lydfiler. Denne gennemløbshastighed er også nyttig ved disk-til-disk-backups. RAID 1 samt andre striping-baserede RAID-niveauer kan forbedre ydeevnen for adgangsmønstre med mange samtidige tilfældige adgangsmønstre, som f.eks. dem, der anvendes af en database med flere brugere.
Hvad RAID ikke kan gøre
- RAID kan ikke beskytte dataene på arrayet. Et RAID-array har ét filsystem. Dette skaber et enkelt fejlpunkt. Der er mange andre ting, der kan ske med dette filsystem end fysiske diskfejl. RAID kan ikke beskytte sig mod disse kilder til datatab. RAID kan ikke forhindre en virus i at ødelægge data. RAID kan ikke forhindre korruption. RAID kan ikke redde data, når en bruger ændrer dem eller sletter dem ved et uheld. RAID beskytter ikke data mod hardwarefejl på andre komponenter end fysiske diske. RAID beskytter ikke data mod naturkatastrofer eller menneskeskabte katastrofer som f.eks. brande og oversvømmelser. For at beskytte data skal der tages backup af dem på flytbare medier, f.eks. dvd, bånd eller en ekstern harddisk. Sikkerhedskopien skal opbevares et andet sted. RAID alene forhindrer ikke, at en katastrofe, når (ikke hvis) den indtræffer, bliver til datatab. Katastrofer kan ikke forhindres, men med sikkerhedskopiering kan tab af data forhindres.
- RAID kan ikke forenkle katastrofeberedskab. Når du kører en enkelt disk, kan disken bruges af de fleste operativsystemer, da de leveres med en fælles enhedsdriver. De fleste RAID-controllere har dog brug for særlige drivere. Genoprettelsesværktøjer, der fungerer med enkelte diske på generiske controllere, kræver særlige drivere for at få adgang til data på RAID-arrays. Hvis disse genoprettelsesværktøjer er dårligt kodet og ikke giver mulighed for at levere yderligere drivere, vil et RAID-array sandsynligvis være utilgængeligt for det pågældende genoprettelsesværktøj.
- RAID kan ikke give et ydelsesløft i alle applikationer. Dette gælder især for typiske brugere af desktop-programmer og gamere. For de fleste desktop-programmer og spil er diskens bufferstrategi og søgeydelse vigtigere end den rå gennemløbskapacitet. En forøgelse af den rå vedvarende overførselshastighed giver kun ringe gevinster for sådanne brugere, da de fleste filer, som de får adgang til, typisk alligevel er meget små. Striping af diske ved hjælp af RAID 0 øger den lineære overførselsydelse, ikke buffer- og søgeydelsen. Som følge heraf viser disk striping med RAID 0 kun en lille eller ingen ydelsesforøgelse i de fleste desktop-programmer og spil, selv om der er undtagelser. For desktopbrugere og gamere med høj ydeevne som mål er det bedre at købe en hurtigere, større og dyrere enkelt disk end at køre to langsommere/mindre diske i RAID 0. Selv ved at køre de nyeste, største og største diske i RAID-0 er det usandsynligt, at ydelsen øges med mere end 10 %, og ydelsen kan falde i visse adgangsmønstre, især i spil.
- Det er vanskeligt at flytte RAID til et nyt system. Med en enkelt disk er det relativt nemt at flytte disken til et nyt system. Den kan blot tilsluttes det nye system, hvis det har samme grænseflade til rådighed. Det er dog ikke så let med et RAID-array. Der er en vis form for metadata, der fortæller, hvordan RAID'en er sat op. En RAID BIOS skal være i stand til at læse disse metadata, så den kan konstruere arrayet med succes og gøre det tilgængeligt for et styresystem. Da producenterne af RAID-controllere bruger forskellige formater til deres metadata (selv controllere af forskellige familier fra samme producent kan bruge inkompatible metadataformater), er det næsten umuligt at flytte et RAID-array til en anden controller. Når man flytter et RAID-array til et nyt system, bør man planlægge at flytte controlleren med. Med populariteten af integrerede RAID-controllere på bundkortet er dette yderst vanskeligt. Generelt er det muligt at flytte RAID-arraymedlemmerne og controllerne sammen. Software-RAID i Linux- og Windows Server-produkter kan også omgå denne begrænsning, men software-RAID har andre begrænsninger (hovedsagelig ydelsesrelaterede).
Eksempel
De RAID-niveauer, der oftest anvendes, er RAID 0, RAID 1 og RAID 5. Lad os antage, at der er tale om en opsætning med 3 diske med 3 identiske diske på hver 1 TB, og at sandsynligheden for fejl på et drev i et givet tidsrum er 1 %.
| RAID-niveau | Anvendelig kapacitet | Sandsynlighed for fejl angivet i procent | Sandsynlighed for fejl 1 ud af ... tilfælde mislykkes |
| 0 | 3 TB | 2,9701% | 34 |
| 1 | 1 TB | 0,0001% | 1 million |
| 5 | 2 TB | 0,0298% | 3356 |
Forfatter
AlegsaOnline.com RAID-guide: Forklaring, niveauer, fordele og ulemper Leandro Alegsa
URL: https://da.alegsaonline.com/art/80859
Kilder
- www-2.cs.cmu.edu : ""A Case for Redundant Arrays of Inexpensive Disks" - Patterson, Gibson, Katz"
- thomason.org : "RAID: High-Performance, Reliable Secondary Storage"
- baarf.com : "BAARF - Battle Against Any Raid Five"
- media.netapp.com : "RAID-DP™: Network Appliance™ implementation of RAID Double Parity for data protection, a high speed implementation of RAID 6"
- nasi.com : "IBM X-Architecture Technology 2001:A design blueprint for Intel processor-based servers"
- pcguide.com : "RAID Level 7"
- cgi.cse.unsw.edu.au : "Linux RAID 10 driver"
- linux-raid.osdl.org : "Main Page - Linux-raid"
- blogs.sun.com : "RAID-Z : Jeff Bonwick's Blog"
- blogs.sun.com : "Adam Leventhal's Weblog"
- research.microsoft.com : "Empirical Measurements of Disk Failure Rates and Error Rates"
- usenix.org : "Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?"
- research.microsoft.com : "The Transaction Concept: Virtues and Limitations (Invited Paper)¦format=pdf"
- informatik.uni-trier.de : "VLDB 1981"
- arxiv.org : "Empirical Measurements of Disk Failure Rates and Error Rates"