Neuralt netværk (ANN) – Hvad er det, og hvordan fungerer det?
Neuralt netværk (ANN) forklaret: Lær hvordan kunstige neuroner, træning og dybdelæring samarbejder i maskinlæring for at løse komplekse problemer.
Et neuralt netværk (også kaldet ANN eller kunstigt neuralt netværk) er en slags computersoftware, der er inspireret af biologiske neuroner. Biologiske hjerner er i stand til at løse vanskelige problemer, men hver neuron er kun ansvarlig for at løse en meget lille del af problemet. På samme måde består et neuralt netværk af celler, der arbejder sammen for at opnå et ønsket resultat, selv om hver enkelt celle kun er ansvarlig for at løse en lille del af problemet. Dette er en metode til at skabe kunstigt intelligente programmer.
Neurale netværk er et eksempel på maskinlæring, hvor et program kan ændres, efterhånden som det lærer at løse et problem. Et neuralt netværk kan trænes og forbedres med hvert enkelt eksempel, men jo større det neurale netværk er, jo flere eksempler skal det bruge for at klare sig godt - ofte skal det bruge millioner eller milliarder af eksempler i tilfælde af dybdeindlæring.
Billedgalleri
6 Billeder

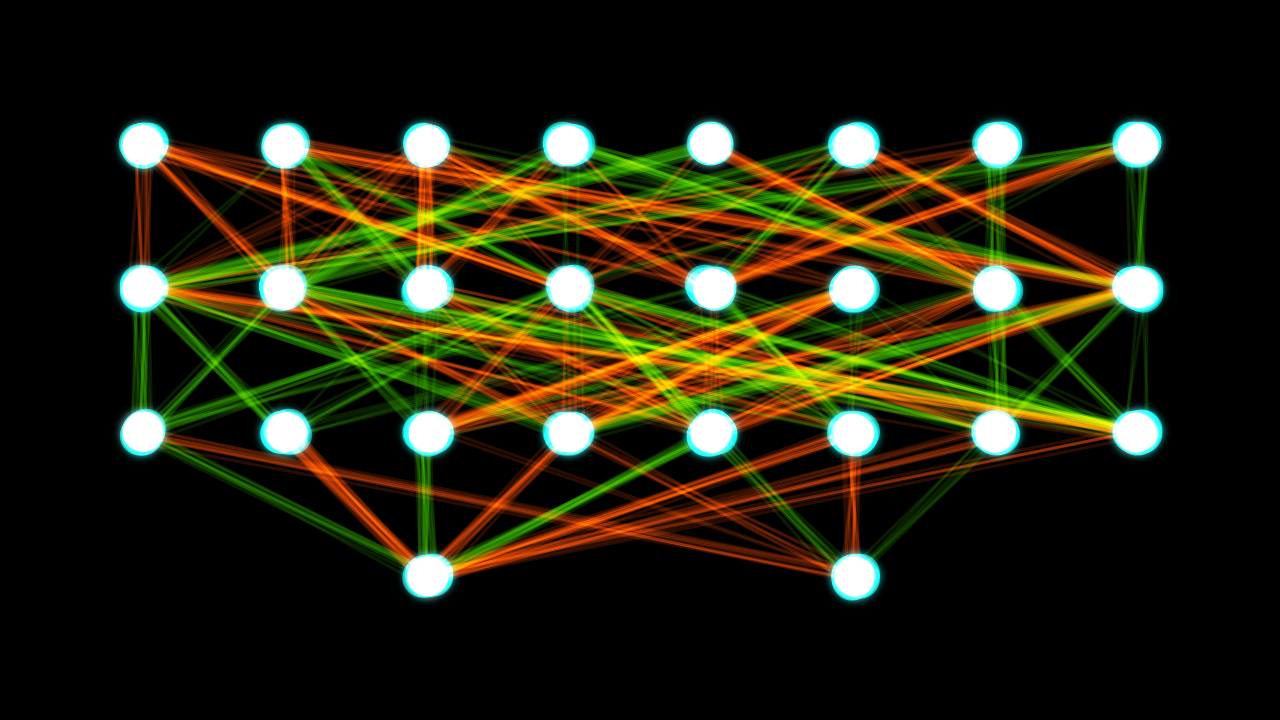



Hvordan er et neuralt netværk opbygget?
Et typisk neuralt netværk består af lag af kunstige neuroner (også kaldet noder eller enheder). De vigtigste lag er:
- Input-laget: Modtager rådata (fx billeder, tekst eller målinger).
- Skjulte lag: Et eller flere lag, hvor netværket bearbejder informationen via vægte og aktiveringsfunktioner.
- Output-laget: Leverer netværkets endelige resultat (klassifikation, regression, sandsynligheder osv.).
Hver forbindelse mellem neuroner har en vægt (et tal), og hver neuron kan have en bias (et justeringsterm). Når netværket får et input, vægtes, summeres og transformeres signalerne i hver neuron ved hjælp af en aktiveringsfunktion, før det sendes videre til næste lag.
Træning: hvordan lærer et neuralt netværk?
Træning handler om at justere vægtene, så netværkets output bliver så korrekt som muligt. De centrale komponenter er:
- Loss-funktion: Et mål for hvor langt netværkets output ligger fra det ønskede svar (fx tværsnitsfejl, krydsentropi).
- Backpropagation: En algoritme til at beregne gradienten af loss i forhold til hver vægt ved hjælp af kædereglen. Gradienterne fortæller, i hvilken retning vægtene skal ændres.
- Optimeringsmetode: Algoritmer som gradient descent, SGD, Adam osv., som bruger gradienter til at opdatere vægtene i små trin.
Træningen foregår ofte i mini-batches (små portioner af træningsdata) over mange epoch (gennemløb af hele datasættet). Performance måles efterhånden på et separat valideringssæt for at afgøre, om modellen generaliserer til nye data.
Aktiveringsfunktioner og deres rolle
Aktiveringsfunktioner introducerer ikke-linearitet, som gør det muligt for netværket at lære komplekse mønstre. Almindelige aktiveringsfunktioner er:
- Sigmoid: Giver output i intervallet (0,1). Bruges sjældnere i skjulte lag pga. problemer med gradientmætning.
- Tanh: Ligner sigmoid, men centreret omkring 0 (interval -1 til 1).
- ReLU (Rectified Linear Unit): Meget udbredt; returnerer 0 for negative input og linear for positive. Hurtig og stabil i dybe netværk.
- Softmax: Bruges i output-laget ved multiclass-klassifikation for at lave sandsynligheder.
Overfitting, regulering og generalisering
Et almindeligt problem er overfitting, hvor modellen lærer træningsdata for godt, inklusive støj, og derfor præsterer dårligt på nye data. Metoder til at undgå overfitting inkluderer:
- Regularisering: L1/L2-vægttildeling (straffe for store vægte).
- Dropout: Tilfældig deaktivering af neuroner under træning for at forhindre afhængighed.
- Dataaugmentation: Kunstig udvidelse af træningsdata (fx rotere eller beskære billeder).
- Early stopping: Stoppe træningen når valideringsfejlen begynder at stige.
Typer af neurale netværk
Der findes mange arkitekturer, tilpasset forskellige opgaver:
- Feedforward-netværk: Simpelt flow fra input til output, bruges til grundlæggende klassifikation og regression.
- Convolutional Neural Networks (CNN): Specialiseret til billed- og videodata; bruger convolution-filtre til at udtrække lokale mønstre.
- Recurrent Neural Networks (RNN) og LSTM/GRU: Designet til sekvensdata som tekst eller tidsserier, hvor tidligere input påvirker senere output.
- Transformer-arkitektur: Bruger opmærksomhedsmechanismer (attention) og er i dag førende inden for behandling af tekst og store sprogmodeller.
Anvendelser
Neurale netværk bruges i dag bredt, fx:
- Billedgenkendelse og medicinsk billeddiagnostik.
- Talegenkendelse og syntese.
- Naturlig sprogbehandling: oversættelse, chatbots, tekstanalyse.
- Autonome systemer og robotik.
- Rekommendationssystemer og finansiel modellering.
Fordele og begrænsninger
Fordele:
- Meget fleksible og i stand til at lære komplekse ikke-lineære relationer.
- Kan automatisk udtrække relevante træk fra rådata (især i dybe netværk).
Begrænsninger:
- Kræver ofte store mængder mærkede data og betydelig regnekraft.
- Kan være svære at tolke (forklarbarhed) — ofte omtalt som "black boxes".
- Risiko for bias, hvis træningsdata ikke er repræsentativt.
Praktiske råd
Når du vil arbejde med neurale netværk, kan disse trin hjælpe:
- Start med en simpel model og baseline før du øger kompleksiteten.
- Del dine data i trænings-, validerings- og test-sæt.
- Overvåg både trænings- og valideringsfejl for at opdage overfitting.
- Prøv forskellige arkitekturer, aktiveringsfunktioner og optimeringsmetoder.
- Brug forbehandling og dataaugmentation hvor det giver mening.
Samlet set er neurale netværk et kraftfuldt værktøj inden for moderne maskinlæring. De gør det muligt at løse komplekse opgaver inden for billed- og talesystemer, tekstforståelse og meget andet, men de stiller også krav til data, beregningsressourcer og omhyggelig modelvurdering.
Oversigt
Et neuralt netværk modellerer et netværk af neuroner, som dem i den menneskelige hjerne. Hver neuron udfører enkle matematiske operationer: den modtager data fra andre neuroner, ændrer dem og sender dem til andre neuroner. Neuroner er placeret i "lag": en neuron fra et lag modtager data fra neuroner i andre lag, ændrer dem og sender data til neuroner i andre lag. Et neuralt netværk består af et eller flere lag.
Det første lag kaldes "inputlaget" og modtager data fra omverdenen (f.eks. et billede eller tekst). Det sidste lag kaldes "udgangslaget". Dataene fra neuronerne i outputlaget læses og bruges som netværkets output. De andre lag kaldes de "skjulte lag".
I et simpelt "feed-forward"-netværk er de data, der behandles af neuronerne, tal. Hver neuron foretager en vægtet sum af værdien af neuronerne i det foregående lag (  i nedenstående ligning). Derefter lægges der en konstant værdi (kaldet "bias") til. Endelig anvender det en matematisk funktion på denne værdi, kaldet "aktiveringsfunktionen". Aktiveringsfunktionen er normalt en funktion, der returnerer en værdi mellem 0 og 1, som f.eks. tanh. Resultatet af aktiveringsfunktionen (
i nedenstående ligning). Derefter lægges der en konstant værdi (kaldet "bias") til. Endelig anvender det en matematisk funktion på denne værdi, kaldet "aktiveringsfunktionen". Aktiveringsfunktionen er normalt en funktion, der returnerer en værdi mellem 0 og 1, som f.eks. tanh. Resultatet af aktiveringsfunktionen (  i nedenstående ligning) sendes derefter til neuronerne i det næste lag.
i nedenstående ligning) sendes derefter til neuronerne i det næste lag.

Der defineres en tabsfunktion for netværket. Tabsfunktionen forsøger at vurdere, hvor godt det neurale netværk klarer den tildelte opgave. Endelig anvendes en optimeringsteknik til at minimere udfaldet af omkostningsfunktionen ved at ændre netværksvægtene og biaserne i netværket. Denne proces kaldes træning. Træning foregår et lille skridt ad gangen. Efter tusindvis af trin er netværket typisk i stand til at udføre sin tildelte opgave ret godt.
Eksempel
Overvej et program, der kontrollerer, om en person er i live. Det kontrollerer to ting - pulsen og åndedrættet. Hvis en person enten har en puls eller trækker vejret, vil programmet udgive "levende", ellers vil det udgive "død". I et program, der ikke lærer over tid, ville dette blive skrevet som:
function isAlive(puls, vejrtrækning) { if(puls || vejrtrækning) { return true; } else { return false; } }
Et meget simpelt neuralt netværk, der kun består af én neuron, og som løser det samme problem, ser således ud:
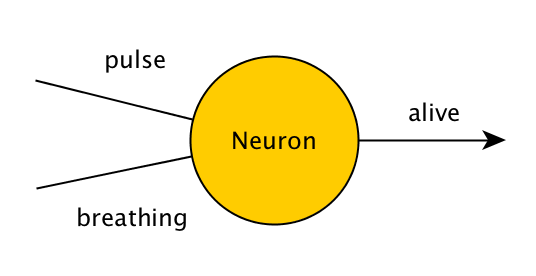
Værdierne for puls, vejrtrækning og levende vil være enten 0 eller 1, hvilket repræsenterer falsk og sandt. Hvis denne neuron får værdierne (0,1), (1,0) eller (1,1), skal den altså udstede 1, og hvis den får (0,0), skal den udstede 0. Neuronen gør dette ved at anvende en simpel matematisk operation på input - den lægger de værdier, den har fået, sammen og tilføjer derefter sin egen skjulte værdi, som kaldes en "bias". Til at begynde med er denne skjulte værdi tilfældig, og vi justerer den med tiden, hvis neuronet ikke giver os det ønskede output.
Hvis vi lægger værdier som (1,1) sammen, kan vi få tal større end 1, men vi ønsker, at vores output skal ligge mellem 0 og 1! For at løse dette kan vi anvende en funktion, som begrænser vores faktiske output til 0 eller 1, selv om resultatet af neuronets matematik ikke lå inden for intervallet. I mere komplicerede neurale netværk anvender vi en funktion (f.eks. sigmoid) på neuronet, så dets værdi bliver mellem 0 eller 1 (f.eks. 0,66), og derefter sender vi denne værdi videre til det næste neuron hele vejen, indtil vi har brug for vores output.
Indlæringsmetoder
Der er tre måder, hvorpå et neuralt netværk kan lære: overvåget læring, uovervåget læring og forstærkende læring. Disse metoder fungerer alle ved enten at minimere eller maksimere en omkostningsfunktion, men de er hver især bedre til bestemte opgaver.
For nylig brugte et forskerhold fra University of Hertfordshire i Storbritannien forstærkende læring til at få en iCub humanoid robot til at lære at sige enkle ord ved at pludre.
Spørgsmål og svar
Spørgsmål: Hvad er et neuralt netværk?
A: Et neuralt netværk (også kaldet ANN eller kunstigt neuralt netværk) er en slags computersoftware, der er inspireret af biologiske neuroner. Det består af celler, der arbejder sammen for at opnå et ønsket resultat, selv om hver enkelt celle kun er ansvarlig for at løse en lille del af problemet.
Spørgsmål: Hvordan kan et neuralt netværk sammenlignes med biologiske hjerner?
Svar: Biologiske hjerner er i stand til at løse vanskelige problemer, men hver enkelt neuron er kun ansvarlig for at løse en meget lille del af problemet. På samme måde består et neuralt netværk af celler, der arbejder sammen for at opnå et ønsket resultat, selv om hver enkelt celle kun er ansvarlig for at løse en lille del af problemet.
Spørgsmål: Hvilken type program kan skabe kunstigt intelligente programmer?
Svar: Neurale netværk er et eksempel på maskinlæring, hvor et program kan ændre sig, efterhånden som det lærer at løse et problem.
Spørgsmål: Hvordan kan man træne og forbedre sig med hvert enkelt eksempel for at bruge dyb læring?
Svar: Et neuralt netværk kan trænes og forbedres med hvert enkelt eksempel, men jo større det neurale netværk er, jo flere eksempler skal det bruge for at klare sig godt - ofte skal det bruge millioner eller milliarder af eksempler i forbindelse med dybdegående læring.
Spørgsmål: Hvad skal man bruge for at få succes med deep learning?
A: For at dybdeindlæring kan lykkes, skal man have millioner eller milliarder af eksempler, afhængigt af hvor stort det neurale netværk er.
Spørgsmål: Hvordan hænger maskinlæring sammen med at skabe kunstigt intelligente programmer?
A: Maskinlæring er relateret til at skabe kunstigt intelligente programmer, fordi den gør det muligt for programmer at ændre sig, efterhånden som de lærer at løse problemer.
Relaterede artikler
Forfatter
AlegsaOnline.com Neuralt netværk (ANN) – Hvad er det, og hvordan fungerer det? Leandro Alegsa
URL: https://da.alegsaonline.com/art/6353
Kilder
- newscientist.com : "Baby robot learns first words from human teacher"