Standardfejl: Forklaring, beregning og tolkning for stikprøver
Forstå standardfejl for stikprøver: klar forklaring, beregning, tolkning og praktiske eksempler for sikre estimater og bedre statistiske beslutninger.
Standardfejlen er standardafvigelsen af stikprøvefordelingen af en statistik. Udtrykket kan også bruges om et skøn (et godt gæt) af denne standardafvigelse, der er taget ud fra en stikprøve af hele gruppen.
Gennemsnittet af en del af en gruppe (kaldet en stikprøve) er den sædvanlige måde at estimere gennemsnittet for hele gruppen på. Det er ofte for vanskeligt eller koster for mange penge at måle hele gruppen. Men hvis man måler en anden stikprøve, vil den få et gennemsnit, der er lidt anderledes end den første stikprøve. Standardfejlen for gennemsnittet er en måde at vide, hvor tæt gennemsnittet af stikprøven ligger på gennemsnittet for hele gruppen. Det er en måde at vide, hvor sikker man kan være på gennemsnittet fra stikprøven.
I virkelige målinger er den sande værdi af standardafvigelsen af gennemsnittet for hele gruppen normalt ikke kendt. Derfor anvendes udtrykket standardfejl ofte som et tæt gæt på det sande tal for hele gruppen. Jo flere målinger der er i en stikprøve, jo tættere vil gættet være på det sande tal for hele gruppen.
Billedgalleri
3 Billeder

Hvad er forskellen på standardafvigelse og standardfejl?
- Standardafvigelsen (SD) beskriver spredningen i de enkelte observationer i en stikprøve eller population: hvor meget værdierne typisk afviger fra gennemsnittet.
- Standardfejlen (SE) beskriver spredningen af en statistisk funktion (fx stikprøvegennemsnittet) når vi gentagne gange tager stikprøver fra samme population. SE måler usikkerheden i estimatet.
- En nyttig intuition: SD handler om variation mellem personer/observationer; SE handler om variation mellem stikprøve-estimater.
Beregning af standardfejl
Der er forskellige formler afhængig af hvilken statistik, man estimerer:
- Standardfejl for gennemsnittet (når man bruger stikprøvens standardafvigelse s som skøn for populations-σ):
SE = s / sqrt(n)
hvor s er stikprøvens standardafvigelse og n er stikprøvestørrelsen. - Standardfejl for et populationsgennemsnit (hvis populations-σ er kendt):
SE = σ / sqrt(n). - Standardfejl for en andel (proportion):
SE = sqrt( p*(1 - p) / n )
hvor p er andelen i stikprøven (eller et antaget populations-estimat).
Bemærk: Når populationsstørrelsen N ikke er meget større end stikprøven (fx når n > 5% af N), kan man korrigere med en såkaldt finite population correction (FPC):
FPC = sqrt( (N - n) / (N - 1) )
Så justeres SE ved at multiplicere med FPC.
Tilknytning til konfidensintervaller og hypotesetest
- Standardfejlen er den centrale størrelse i konfidensintervaller: et 95% konfidensinterval for et gennemsnit er ofte givet ved
gennemsnit ± z*SE (hvor z ≈ 1.96 hvis populations-σ kendes og normalfordelingen kan anvendes), eller
gennemsnit ± t_{n-1}*SE (hvor t er t-fordelingens kritiske værdi, når σ estimeres fra stikprøven). - I hypotesetest bruges SE til at standardisere forskelle (f.eks. t- eller z-statistik) og dermed vurdere, om en observeret forskel kan skyldes tilfældighed.
Hvornår bruger man t-fordeling fremfor z-fordeling?
- Hvis populations-σ er ukendt (det mest almindelige), og du estimerer den med stikprøvens s, bør du bruge t-fordelingen—særligt ved små stikprøver (typisk n < 30).
- Ved store stikprøver giver t- og z-fordelingen næsten samme svar, så z-tilnærmelsen kan være acceptabel.
Tolkning og praktiske eksempler
- Eksempel 1 (gennemsnit): Hvis s = 15 og n = 25, så er SE = 15 / sqrt(25) = 3. Et 95% CI (med z ≈ 1.96) er gennemsnit ± 1.96*3 ≈ gennemsnit ± 5.88.
- Eksempel 2 (andel): Hvis p = 0.6 og n = 100, så er SE = sqrt(0.6*0.4/100) ≈ 0.049. Et 95% CI cirka p ± 1.96*SE ≈ 0.6 ± 0.096.
- Størrelseseffekt: SE falder som 1/sqrt(n). For at halvere SE skal stikprøven ganges med fire.
Almindelige fejl og gode råd
- Forveksling af SD og SE: Husk at SD beskriver spredning i data, mens SE beskriver usikkerheden i et estimat.
- Brug t-fordeling når σ ikke er kendt og stikprøven er lille.
- Sørg for, at betingelserne for normaltilnærmelse er opfyldt ved brug af formler (fx for andele: np og n(1−p) må ikke være for små).
- Tag finite population correction i brug, når stikprøven udgør en ikke-ubetydelig del af populationen.
- Rapportér både estimat og SE (eller konfidensinterval) for at give et klart billede af usikkerheden.
Sammenfatning
Standardfejlen kvantificerer usikkerheden i et stikprøvestatistik som fx gennemsnittet eller en andel. Den beregnes typisk ved SE = s / sqrt(n) for gennemsnittet eller SE = sqrt(p(1−p)/n) for andele. Mindre SE betyder større præcision i estimatet. Ved ukendt populations-σ og små stikprøver skal man bruge t-fordelingen; ved store stikprøver er z-tilnærmelsen ofte tilstrækkelig.

Sådan finder du standardfejl i middelværdien
En måde at finde middelværdiens standardfejl på er at have mange stikprøver. Først finder man gennemsnittet for hver prøve. Derefter finder man gennemsnittet og standardafvigelsen af disse gennemsnit af prøverne. Standardafvigelsen for alle gennemsnit af prøverne er middelværdiens standardafvigelse. Dette kan være et stort arbejde. Nogle gange er det for vanskeligt eller koster for mange penge at have mange prøver.
En anden måde at finde middelværdienes standardafvigelse på er at bruge en ligning, som kun kræver én prøve. Middelværdighedens standardfejl estimeres normalt ved at dividere standardafvigelsen for en stikprøve fra hele gruppen (stikprøvens standardafvigelse) med kvadratroden af stikprøvens størrelse.
S E x ¯ = s n {\displaystyle SE_{\bar {x}}}\ ={\frac {s}{\sqrt {n}}}} 
hvor
s er stikprøvens standardafvigelse (dvs. det stikprøvebaserede skøn over populationens standardafvigelse), og
n er antallet af målinger i prøven.
Hvor stor skal stikprøven være, for at estimatet af middelværdiens standardfejl ligger tæt på den faktiske standardfejl for hele gruppen? Der skal være mindst seks målinger i en stikprøve. Så vil standardfejlen for middelværdien for stikprøven ligge inden for 5 % af standardfejlen for middelværdien, hvis hele gruppen var blevet målt.
Rettelser i nogle tilfælde
Der er en anden ligning, der skal anvendes, hvis antallet af målinger udgør 5 % eller mere af hele gruppen:
Der er særlige ligninger, der skal anvendes, hvis en prøve har færre end 20 målinger.
Nogle gange kommer en prøve fra ét sted, selv om hele gruppen måske er spredt ud. Det kan også ske, at en stikprøve bliver taget i en kort periode, mens hele gruppen dækker et længere tidsrum. I dette tilfælde er tallene i stikprøven ikke uafhængige. I så fald anvendes særlige ligninger for at forsøge at korrigere for dette.
Anvendelighed
Et praktisk resultat: Man kan blive mere sikker på en gennemsnitsværdi ved at have flere målinger i en prøve. Så bliver middelværdienes standardafvigelse mindre, fordi standardafvigelsen divideres med et større tal. Men for at gøre usikkerheden (standardfejl i middelværdien) i en gennemsnitsværdi halvt så stor skal stikprøvestørrelsen (n) være fire gange større. Det skyldes, at standardafvigelsen divideres med kvadratroden af stikprøvestørrelsen. For at gøre usikkerheden en tiendedel så stor skal stikprøvestørrelsen (n) være hundrede gange større!
Standardfejl er nemme at beregne og bruges meget, fordi:
- Hvis standardfejlen for flere individuelle størrelser er kendt, kan standardfejlen for en funktion af disse størrelser i mange tilfælde let beregnes;
- Når sandsynlighedsfordelingen for værdien er kendt, kan den bruges til at beregne en god tilnærmelse til et nøjagtigt konfidensinterval, og
- Når sandsynlighedsfordelingen ikke er kendt, kan andre ligninger anvendes til at estimere et konfidensinterval
- Når stikprøvens størrelse bliver meget stor, viser princippet i den centrale grænsesætning, at tallene i stikprøven ligner tallene i hele gruppen meget (de har en normalfordeling).
Relativ standardfejl
Den relative standardfejl (RSE) er standardfejlen divideret med gennemsnittet. Dette tal er mindre end et. Ved at gange det med 100 % fås det som en procentdel af gennemsnittet. Dette er med til at vise, om usikkerheden er vigtig eller ej. Tag f.eks. to undersøgelser af husstandsindkomst, som begge resulterer i et stikprøvegennemsnit på 50 000 USD. Hvis den ene undersøgelse har en standardfejl på 10 000 USD og den anden har en standardfejl på 5 000 USD, er de relative standardfejl henholdsvis 20 % og 10 %. Undersøgelsen med den lavere relative standardfejl er bedre, fordi den har en mere præcis måling (usikkerheden er mindre).
Faktisk beslutter folk, der har brug for at kende gennemsnitsværdierne, ofte, hvor lille usikkerheden skal være, før de beslutter sig for at bruge oplysningerne. F.eks. rapporterer det amerikanske National Center for Health Statistics ikke et gennemsnit, hvis den relative standardfejl overstiger 30 %. NCHS kræver også mindst 30 observationer, for at et skøn kan rapporteres. []
Eksempel
Der er f.eks. mange rødfisk i vandet i Den Mexicanske Golf. For at finde ud af, hvor meget en 42 cm lang rødfisk i gennemsnit vejer, er det ikke muligt at måle alle de rødfisk, der er 42 cm lange. I stedet er det muligt at måle nogle af dem. De fisk, der faktisk måles, kaldes en prøve. Tabellen viser vægtene for to prøver af rødfisk, der alle er 42 cm lange. Gennemsnitsvægten (middelvægten) for den første prøve er 0,741 kg. Gennemsnitsvægten (gennemsnitsvægten) for den anden prøve er 0,735 kg, hvilket er en smule anderledes end for den første prøve. Hvert af disse gennemsnit er en lille smule forskelligt fra det gennemsnit, der ville fremkomme ved at måle hver enkelt 42 cm lang rødfisk (hvilket alligevel ikke er muligt).
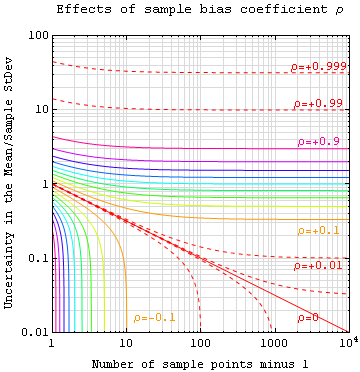
Usikkerheden i middelværdien kan bruges til at finde ud af, hvor tæt gennemsnittet af stikprøverne ligger på det gennemsnit, der ville fremkomme ved at måle hele gruppen. Usikkerheden i middelværdien anslås som standardafvigelsen for stikprøven divideret med kvadratroden af antallet af stikprøver minus 1. Tabellen viser, at usikkerhederne i middelværdierne for de to prøver ligger meget tæt på hinanden. Den relative usikkerhed er ligeledes usikkerheden i middelværdien divideret med middelværdien gange 100 %. Den relative usikkerhed i dette eksempel er 2,38% og 2,50% for de to prøver.
Når man kender usikkerheden på gennemsnittet, kan man vide, hvor tæt gennemsnittet af stikprøven ligger på det gennemsnit, der ville fremkomme ved at måle hele gruppen. Gennemsnittet for hele gruppen ligger mellem a) gennemsnittet for stikprøven plus usikkerheden i middelværdien og b) gennemsnittet for stikprøven minus usikkerheden i middelværdien. I dette eksempel forventes gennemsnitsvægten for alle de 42 cm lange rødfisk i Den Mexicanske Golf at være 0,723-0,759 kg på grundlag af den første prøve og 0,717-0,753 kg på grundlag af den anden prøve.


Spørgsmål og svar
Q: Hvad er standardfejlen?
A: Standardfejlen er standardafvigelsen for stikprøvefordelingen af en statistik.
Q: Kan udtrykket standardfejl bruges om et estimat af standardafvigelsen?
A: Ja, termen standardfejl kan bruges til et estimat (godt gæt) af denne standardafvigelse taget fra en stikprøve af hele gruppen.
Q: Hvordan estimerer man gennemsnittet for en hel gruppe?
A: Gennemsnittet af en del af en gruppe (kaldet en stikprøve) er den sædvanlige måde at estimere gennemsnittet for hele gruppen på.
Q: Hvorfor er det svært at måle hele gruppen?
A: Det er ofte for svært eller for dyrt at måle hele gruppen.
Q: Hvad er standardfejlen for gennemsnittet, og hvad bestemmer den?
A: Standardfejlen på gennemsnittet er en måde at vide, hvor tæt gennemsnittet af stikprøven er på gennemsnittet af hele gruppen. Det er en måde at vide, hvor sikker man kan være på gennemsnittet fra stikprøven.
Q: Kender man normalt den sande værdi af standardafvigelsen for gennemsnittet i virkelige målinger?
A: Nej, den sande værdi af standardafvigelsen for gennemsnittet for hele gruppen er normalt ikke kendt i virkelige målinger.
Q: Hvordan påvirker antallet af målinger i en stikprøve nøjagtigheden af estimatet?
A: Jo flere målinger der er i en stikprøve, jo tættere vil gættet være på det sande tal for hele gruppen.
Relaterede artikler
Forfatter
AlegsaOnline.com Standardfejl: Forklaring, beregning og tolkning for stikprøver Leandro Alegsa
URL: https://da.alegsaonline.com/art/93322
Kilder
- doi.org : 10.2307/2682923
- jstor.org : 2682923
- doi.org : 10.2307/2340569
- jstor.org : 2340569