Mikroarkitektur: CPU'ens interne design, kredsløb og funktion
Dyk ned i mikroarkitekturens verden: CPU'ens interne design, kredsløb og funktion forklaret klart for ingeniører og nysgerrige — forstå hvordan hardware styrer ydeevnen.
Inden for computerteknik er mikroarkitektur (undertiden forkortet µarch eller uarch) en beskrivelse af de elektriske kredsløb i en computer, en central processorenhed eller en digital signalprocessor, som er tilstrækkelig til at beskrive hardwarens funktion fuldstændigt.
Forskere bruger udtrykket "computerorganisation", mens folk i computerindustrien oftere bruger udtrykket "mikroarkitektur". Mikroarkitektur og instruktionssætarkitektur (ISA) udgør tilsammen området computerarkitektur.
Billedgalleri
1 Billede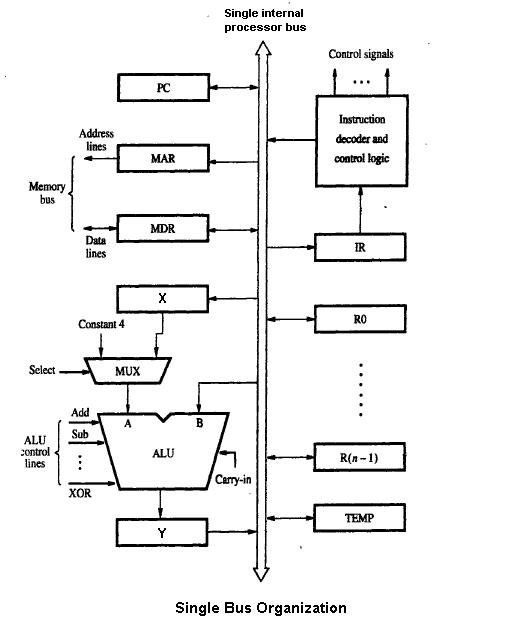
Hvad dækker mikroarkitektur over?
Mikroarkitektur beskriver den interne opbygning og de kredsløb, som gør det muligt for en processor at udføre instruktioner defineret af ISA'en. Den omfatter både funktionelle enheder og styringslogik, og går fra registerniveau til lave niveauers kredsløbsdesign. Eksempler på centrale dele:
- Instruktionshent og -dekodning: logik der henter instruktioner fra hukommelse eller cache og oversætter dem til interne mikro-operationer.
- Pipeline-stadier: opdeling af arbejdet i f.eks. fetch, decode, execute, memory og write-back for at øge gennemløb.
- Aritmetisk/Logisk Enhed (ALU) og FPU: de enheder der udfører beregninger og floating-point operationer.
- Registre og registerfil: hurtig lokal lagring til CPU-instruktioner og data.
- Cache og hukommelsesstyring: niveauer af cache, TLB'er og hukommelsescontroller for at reducere adgangstid til data.
- Kontrol- og styringslogik: pipeline-kontrol, interrupts, exceptions og kontekstskifte.
- Spekulation og branch prediction: mekanismer der forudsiger kontrolflow for at holde pipeline fyldt.
- Out-of-order execution og reorder buffers: muliggør at uafhængige instruktioner udføres i anden rækkefølge for bedre udnyttelse af enheder.
- Multicore og coherency-mekanismer: design for flere kerner, delte caches og hukommelseskonsistens.
Vigtige designvalg og trade-offs
Mikroarkitekter afvejer ofte tre hovedparametre: ydelse, strømforbrug og område (chipareal). Nogle typiske valg:
- RISC vs. CISC: Simple, faste instruktioner (RISC) gør ofte pipeline-design enklere; komplekse instruktioner (CISC) kan kræve mikroprogrammering eller ekstra dekodning.
- Pipelining og superskalaritet: Flere parallelle pipeline-lanes (superscalar) øger throughput, men øger kompleksiteten for hazard-håndtering.
- In-order vs. out-of-order: Out-of-order kan give bedre ydelse under afhængigheder, men koster mere logik og strøm.
- Cache-størrelse og hierarki: Større caches mindsker hukommelseslatens men øger latenstid og forbrug.
Mikrokode og implementering
Nogle processorer bruger mikrokode (microcode) som et lag mellem ISA og de underliggende kredsløb — især ved komplekse CISC-instruktioner. Mikroarkitektur specificeres typisk i register-transfer level (RTL) sprog som Verilog eller VHDL, simuleres og verificeres, før den syntheses til gates og fysisk layout.
Ydelsesproblemer og løsninger
Typiske udfordringer i mikroarkitektur:
- Data hazards: afhængigheder mellem instruktioner løses med forwarding, stalling eller omrokering.
- Kontrolhazards: branch prediction og spekulativ udførelse minimerer pipeline-pauser ved forgreninger.
- Cache-misses og hukommelseslatens: prefetching, større eller flerlaget cache og non-blocking caches hjælper.
Verifikation, test og sikkerhed
Mikroarkitekturer kræver omfattende verifikation: funktionel verifikation, formel verifikation, timing-analyse og test (ATE). Moderne mikroarkitekturer skal også tage højde for sikkerhedsrisici som sidekanalangreb og sårbarheder relateret til spekulativ udførelse (fx rowhammer-relaterede eller spekulationsbaserede angreb), hvilket kan påvirke designvalg for spekulation og isolation.
Anvendelser og variationer
Mikroarkitektur findes ikke kun i traditionelle CPU'er, men også i digital signalprocessorer, GPU'er, system-on-chip (SoC) løsninger og specialiserede acceleratorer. Hver klasse af enheder prioriterer forskellige egenskaber: lavt strømforbrug i mobil-SoC'er, høj gennemløb i server-CPU'er, eller massiv parallelisme i GPU'er.
Relation til instruktionssætarkitektur
ISA'en definerer hvad en processor kan gøre (instruktionssemantik, registrer, adresseringsformer), mens mikroarkitekturen beskriver hvordan disse instruktioner realiseres i hardware. To forskellige mikroarkitekturer kan implementere den samme ISA; omvendt kan en mikroarkitektur designes til at understøtte flere ISAs eller udvidelser.
Afsluttende bemærkninger
Mikroarkitektur er broen mellem abstrakt maskinmodel (ISA) og fysisk kredsløbsimplementering. Forståelse af mikroarkitektur er essentiel for at designe effektive og sikre processorer, optimere software og evaluere ydeevne i forskellige anvendelsesscenarier.
Udtrykkets oprindelse
Computere har anvendt mikroprogrammering af styrelogik siden 1950'erne. CPU'en afkoder instruktionerne og sender signaler ned ad de relevante stier ved hjælp af transistorkontakter. Bitsene i mikroprogramordene styrer processoren på niveauet for elektriske signaler.
Udtrykket: mikroarkitektur blev brugt til at beskrive de enheder, der blev styret af mikroprogramordene, i modsætning til udtrykket: "arkitektur", som var synlig og dokumenteret for programmører. Mens arkitekturen normalt skulle være kompatibel mellem forskellige hardwaregenerationer, kunne den underliggende mikroarkitektur let ændres.
Forhold til instruktionssætarkitekturen
Mikroarkitekturen er beslægtet med, men ikke det samme som instruktionssætarkitekturen. Instruktionssætarkitekturen er tæt på en processors programmeringsmodel, som den ses af en programmør af assemblagesprog eller en compilerforfatter, og som omfatter udførelsesmodellen, processorregistre, hukommelsesadressemåder, adresse- og dataformater osv. Mikroarkitekturen (eller computerorganisationen) er hovedsageligt en struktur på et lavere niveau og styrer derfor et stort antal detaljer, som er skjult i programmeringsmodellen. Den beskriver processorens indre dele, og hvordan de arbejder sammen for at gennemføre den arkitektoniske specifikation.
Mikroarkitektoniske elementer kan være alt fra enkelte logiske gates til registre, opslagstabeller, multiplexere, tællere osv. til komplette ALU'er, FPU'er og endnu større elementer. Det elektroniske kredsløbsniveau kan igen underopdeles i detaljer på transistorniveau, f.eks. hvilke grundlæggende strukturer til opbygning af porte der anvendes, og hvilke logikimplementeringstyper (statisk/dynamisk, antal faser osv.) der vælges, ud over det egentlige logikdesign, der anvendes til at opbygge dem.
Et par vigtige punkter:
- En enkelt mikroarkitektur, især hvis den indeholder mikrokode, kan bruges til at implementere mange forskellige instruktionssæt ved at ændre kontrollageret. Dette kan imidlertid være ret kompliceret, selv når det er forenklet med mikrokode og/eller tabelstrukturer i ROM'er eller PLA'er.
- To maskiner kan have den samme mikroarkitektur og dermed det samme blokdiagram, men helt forskellige hardwareimplementeringer. Dette gælder både på det elektroniske kredsløbsniveau og i endnu højere grad på det fysiske fremstillingsniveau (af både IC'er og/eller diskrete komponenter).
- Maskiner med forskellige mikroarkitekturer kan have den samme instruktionssætarkitektur, og derfor kan begge maskiner udføre de samme programmer. Nye mikroarkitekturer og/eller kredsløsninger samt fremskridt inden for halvlederfremstilling gør det muligt for nyere generationer af processorer at opnå højere ydeevne.
Forenklede beskrivelser
En meget forenklet beskrivelse på højt niveau - som er almindelig i markedsføringen - kan kun vise ret grundlæggende egenskaber, f.eks. busbredder, sammen med forskellige typer af udførelsesenheder og andre store systemer, f.eks. forgreningsforudsigelse og cache-hukommelser, der er afbildet som enkle blokke - måske med nogle vigtige egenskaber eller karakteristika noteret. Nogle detaljer vedrørende pipeline-strukturen (som f.eks. hentning, afkodning, tildeling, udførelse og tilbageskrivning) kan også være medtaget.
Aspekter af mikroarkitekturen
Pipelined datapath er det mest almindeligt anvendte datapath-design i mikroarkitekturen i dag. Denne teknik anvendes i de fleste moderne mikroprocessorer, mikrocontrollere og DSP'er. Med pipelined-arkitekturen kan flere instruktioner overlappe hinanden i udførelsen, ligesom i en samlebåndslinje. Pipelinen omfatter flere forskellige trin, som er grundlæggende i mikroarkitekturdesign. Nogle af disse faser omfatter hentning af instruktioner, afkodning af instruktioner, udførelse og tilbageskrivning. Nogle arkitekturer omfatter andre faser, f.eks. hukommelsesadgang. Udformningen af pipelines er en af de centrale opgaver i mikroarkitekturen.
Eksekveringsenheder er også vigtige for mikroarkitekturen. Udførelsesenheder omfatter aritmetiske logiske enheder (ALU), floating point-enheder (FPU), load/store-enheder og forgreningsforudsigelse. Disse enheder udfører processorens operationer eller beregninger. Valget af antallet af eksekveringsenheder, deres latenstid og gennemløb er vigtige mikroarkitektoniske designopgaver. Størrelsen, latenstiden, gennemstrømningen og forbindelsesmulighederne for hukommelserne i systemet er også mikroarkitektoniske beslutninger.
Beslutninger om design på systemniveau, f.eks. om der skal medtages periferiudstyr, f.eks. hukommelsescontrollere, kan betragtes som en del af den mikroarkitektoniske designproces. Dette omfatter beslutninger om disse periferiers ydeevne og tilslutningsmuligheder.
I modsætning til arkitektonisk design, hvor et bestemt præstationsniveau er hovedmålet, er mikroarkitekturdesign mere opmærksom på andre begrænsninger. Der skal lægges vægt på spørgsmål som f.eks:
- Chip-areal/omkostninger.
- Strømforbrug.
- Logisk kompleksitet.
- Nem tilslutningsmuligheder.
- Fremstillingsmuligheder.
- Let at fejlfinde.
- Testbarhed.
Mikroarkitektoniske koncepter
Generelt kører alle CPU'er, single-chip-mikroprocessorer eller multi-chip-implementeringer, programmer ved at udføre følgende trin:
- Læs en instruktion og afkod den.
- Find eventuelle tilknyttede data, der er nødvendige for at behandle instruktionen.
- Behandling af instruktionen.
- Skriv resultaterne ud.
Det komplicerer denne enkle række af trin, fordi hukommelseshierarkiet, som omfatter caching, hovedhukommelse og ikke-flygtig lagring som f.eks. harddiske (hvor programinstruktionerne og dataene befinder sig), altid har været langsommere end selve processoren. Trin (2) medfører ofte en forsinkelse (i CPU-termer ofte kaldet "stall"), mens dataene ankommer over computerbussen. Der er blevet forsket meget i konstruktioner, der så vidt muligt undgår disse forsinkelser. I årenes løb har et centralt designmål været at udføre flere instruktioner parallelt og dermed øge den effektive udførelseshastighed for et program. Disse bestræbelser introducerede komplicerede logik- og kredsløbsstrukturer. Tidligere kunne sådanne teknikker kun gennemføres på dyre mainframes eller supercomputere på grund af den mængde kredsløb, der var nødvendige for disse teknikker. Efterhånden som halvlederfremstillingen udviklede sig, kunne flere og flere af disse teknikker gennemføres på en enkelt halvlederchip.
I det følgende gives en oversigt over de mikroarkitekturteknikker, der er almindelige i moderne CPU'er.
Valg af instruktionssæt
Valget af hvilken instruktionssætarkitektur der skal anvendes, har stor indflydelse på kompleksiteten af implementeringen af højtydende enheder. I årenes løb har computerdesignere gjort deres bedste for at forenkle instruktionssættene for at muliggøre implementeringer med højere ydeevne ved at spare designerne for kræfter og tid til funktioner, der forbedrer ydeevnen, i stedet for at spilde dem på kompleksiteten af instruktionssættet.
Design af instruktionssæt har udviklet sig fra CISC-, RISC-, VLIW- og EPIC-typer. Arkitekturer, der beskæftiger sig med dataparallelisme, omfatter SIMD og vektorer.
Instruktionspipelining
En af de første og mest effektive teknikker til at forbedre ydeevnen er brugen af instruktionspipeline. De tidlige processordesigns udførte alle ovenstående trin på én instruktion, før de gik videre til den næste. Store dele af processorkredsløbet blev efterladt ubenyttet på et hvilket som helst trin; f.eks. var instruktionsafkodningskredsløbet ubenyttet under udførelsen osv.
Pipelines forbedrer ydeevnen ved at give mulighed for, at en række instruktioner kan arbejde sig gennem processoren på samme tid. I det samme grundlæggende eksempel ville processoren begynde at afkode (trin 1) en ny instruktion, mens den sidste instruktion ventede på resultater. Dette ville gøre det muligt at "afvikle" op til fire instruktioner på én gang, hvilket ville få processoren til at se fire gange så hurtig ud. Selv om en enkelt instruktion tager lige så lang tid at gennemføre (der er stadig fire trin), "pensionerer" CPU'en som helhed instruktionerne meget hurtigere og kan køre med en meget højere taktfrekvens.
Cache
Forbedringer i chipfremstillingen gjorde det muligt at placere flere kredsløb på den samme chip, og designerne begyndte at lede efter måder at bruge dem på. En af de mest almindelige metoder var at tilføje en stadig større mængde cache-hukommelse på chippen. Cache er en meget hurtig hukommelse, en hukommelse, der kan tilgås på få cyklusser sammenlignet med det, der er nødvendigt for at tale med hovedhukommelsen. CPU'en indeholder en cache-controller, som automatiserer læsning og skrivning fra cachen; hvis dataene allerede er i cachen, "dukker de blot op", mens processoren "går i stå", mens cache-controlleren læser dem ind, hvis de ikke er i cachen.
RISC-designs begyndte at tilføje cache i midten og slutningen af 1980'erne, men ofte kun 4 KB i alt. Dette antal voksede med tiden, og typiske CPU'er har nu ca. 512 KB, mens mere kraftfulde CPU'er har 1 eller 2 eller endda 4, 6, 8 eller 12 MB, organiseret i flere niveauer i et hukommelseshierarki. Generelt set betyder mere cache mere hastighed.
Caches og pipelines var et perfekt match for hinanden. Tidligere gav det ikke meget mening at bygge en pipeline, der kunne køre hurtigere end adgangslatenstiden for kontanthukommelse uden for chippen. Ved i stedet at bruge on-chip cache-hukommelse betød det, at en pipeline kunne køre med samme hastighed som cache-adgangslatenstiden, en meget kortere tidsperiode. Dette gjorde det muligt at øge processorernes driftsfrekvenser meget hurtigere end for off-chip-hukommelse.
Forudsigelse af forgrening og spekulativ udførelse
Pipelineforstyrrelser og spolinger på grund af forgreninger er de to vigtigste hindringer for at opnå højere ydeevne ved hjælp af parallelisme på instruktionsniveau. Fra det tidspunkt, hvor processorens instruktionsdekoder har fundet ud af, at den er stødt på en betinget forgreningsinstruktion, til det tidspunkt, hvor den afgørende springregisterværdi kan aflæses, kan pipelinen være gået i stå i flere cyklusser. I gennemsnit er hver femte instruktion, der udføres, en forgrening, så det er et stort antal forsinkelser. Hvis forgreningen gennemføres, er det endnu værre, da alle de efterfølgende instruktioner, der var i pipelinen, skal spules.
Teknikker som forgreningsforudsigelse og spekulativ udførelse anvendes til at reducere disse forgreningsafstraffelser. Forudsigelse af forgrening er, når hardwaren foretager kvalificerede gæt om, hvorvidt en bestemt forgrening vil blive taget. Dette gæt gør det muligt for hardwaren at forudindlæse instruktioner uden at vente på registerlæsning. Speculativ udførelse er en yderligere forbedring, hvor koden langs den forudsagte vej udføres, før det vides, om afgreningen skal tages eller ej.
Udførelse uden for rækkefølge
Tilføjelsen af caches reducerer hyppigheden eller varigheden af de forsinkelser, der skyldes ventetid på data, der skal hentes fra hovedhukommelseshierarkiet, men fjerner ikke disse forsinkelser helt. I de tidlige konstruktioner ville en cache-missing tvinge cache-controlleren til at standse processoren og vente. Der kan naturligvis være en anden instruktion i programmet, hvis data er tilgængelige i cachen på dette tidspunkt. Udførelse uden for rækkefølge gør det muligt at behandle den instruktion, der er klar, mens en ældre instruktion venter i cachen, og derefter omarrangeres resultaterne for at få det til at se ud som om, at alt er sket i den programmerede rækkefølge.
Superscalar
Selv med al den ekstra kompleksitet og de ekstra gates, der var nødvendige for at understøtte de ovenfor beskrevne koncepter, gjorde forbedringer inden for halvlederfremstilling det snart muligt at anvende endnu flere logiske gates.
I skitsen ovenfor behandler processoren dele af en enkelt instruktion ad gangen. Computerprogrammer kunne udføres hurtigere, hvis flere instruktioner blev behandlet samtidig. Det er det, som superskalære processorer opnår ved at gentage funktionelle enheder som f.eks. ALU'er. Replikation af funktionelle enheder blev først mulig, da det integrerede kredsløb (nogle gange kaldet "die") i en enkelt processor ikke længere var så stort, at det ikke længere var muligt at fremstille det på en pålidelig måde. I slutningen af 1980'erne begyndte superscalar-designs at komme på markedet.
I moderne design er det almindeligt at finde to indlæsningsenheder, en lagerenhed (mange instruktioner har ingen resultater at lagre), to eller flere heltalsmatematiske enheder, to eller flere flydende point-enheder og ofte en SIMD-enhed af en eller anden art. Logikken til udstedelse af instruktioner vokser i kompleksitet ved at læse en enorm liste af instruktioner fra hukommelsen og videregive dem til de forskellige udførelsesenheder, der er inaktive på det pågældende tidspunkt. Resultaterne samles og omfordeles så til sidst.
Omdøbning af registre
Registeromdøbning henviser til en teknik, der bruges til at undgå unødvendig serialiseret udførelse af programinstruktioner på grund af genbrug af de samme registre i disse instruktioner. Hvis vi har to grupper af instruktioner, der skal bruge det samme register, udføres det ene sæt instruktioner først for at overlade registret til det andet sæt, men hvis det andet sæt tildeles et andet lignende register, kan begge sæt instruktioner udføres parallelt.
Multiprocessing og multithreading
På grund af den voksende forskel mellem CPU-arbejdsfrekvenserne og DRAM-adgangstiden kunne ingen af de teknikker, der forbedrer parallelitet på instruktionsniveau (ILP) i et program, overvinde de lange forsinkelser, der opstod, når data skulle hentes fra hovedhukommelsen. Desuden krævede de store transistorantal og høje driftsfrekvenser, der var nødvendige for de mere avancerede ILP-teknikker, et strømforbrug, som ikke længere kunne køles billigt. Af disse grunde er nyere generationer af computere begyndt at udnytte højere niveauer af parallelitet, der eksisterer uden for et enkelt program eller en enkelt programtråd.
Denne tendens er undertiden kendt som "throughput computing". Denne idé stammer fra mainframemarkedet, hvor online-transaktionsbehandling ikke blot lagde vægt på udførelseshastigheden for en enkelt transaktion, men også på evnen til at håndtere et stort antal transaktioner på samme tid. Da transaktionsbaserede applikationer som f.eks. netværksrouting og web-site-servering er steget kraftigt i det seneste årti, har computerindustrien igen lagt vægt på kapacitet og gennemløb.
En teknik til at opnå denne parallelitet er multiprocessing-systemer, computersystemer med flere CPU'er. Tidligere var dette forbeholdt avancerede mainframes, men nu er små (2-8) multiprocessorservere blevet almindelige på markedet for små virksomheder. I store virksomheder er det almindeligt med store (16-256) multiprocessorer. Selv personlige computere med flere CPU'er er dukket op siden 1990'erne.
Fremskridt inden for halvlederteknologien reducerede transistorstørrelsen; der er opstået multicore-CPU'er, hvor flere CPU'er er implementeret på den samme siliciumchip. Oprindeligt blev de anvendt i chips til indlejrede markeder, hvor enklere og mindre CPU'er gjorde det muligt at placere flere instantieringer på ét stykke silicium. I 2005 gjorde halvlederteknologien det muligt at fremstille dobbelt high-end desktop-CPU'er CMP-chips i store mængder. Nogle designs, f.eks. UltraSPARC T1, anvendte et enklere design (skalar, in-order) for at få plads til flere processorer på ét stykke silicium.
En anden teknik, der er blevet mere populær i den seneste tid, er multithreading. Ved multithreading skifter processoren, når den skal hente data fra den langsomme systemhukommelse, til et andet program eller en anden programtråd, som er klar til at blive udført, i stedet for at vente på, at dataene kommer frem. Selv om dette ikke fremskynder et bestemt program/en bestemt tråd, øger det den samlede systemgennemstrømning ved at reducere den tid, hvor CPU'en er inaktiv.
Begrebsmæssigt svarer multithreading til et kontekstskifte på operativsystemniveau. Forskellen er, at en CPU med flere tråde kan foretage et trådskifte på én CPU-cyklus i stedet for de hundred- eller tusindvis af CPU-cyklusser, som et kontekstskifte normalt kræver. Dette opnås ved at replikere tilstandshardwaren (f.eks. registerfilen og programtælleren) for hver aktiv tråd.
En yderligere forbedring er samtidig multithreading. Denne teknik gør det muligt for superskalære CPU'er at udføre instruktioner fra forskellige programmer/threads samtidigt i den samme cyklus.
Relaterede sider
- Mikroprocessor
- Mikrocontroller
- Multi-core-processor
- Digital signalprocessor
- CPU-design
- Datapath
- parallelisme på instruktionsniveau (ILP)
Spørgsmål og svar
Spørgsmål: Hvad er mikroarkitektur?
A: Mikroarkitektur er en beskrivelse af de elektriske kredsløb i en computer, en central processorenhed eller en digital signalprocessor, som er tilstrækkelig til at beskrive hardwarens funktion fuldstændigt.
Spørgsmål: Hvordan henviser forskere til dette begreb?
Svar: Forskere bruger udtrykket "computerorganisation", når de henviser til mikroarkitektur.
Spørgsmål: Hvordan omtaler folk i computerindustrien dette begreb?
Svar: Folk i computerbranchen siger oftere "mikroarkitektur", når de henviser til dette begreb.
Spørgsmål: Hvilke to områder udgør computerarkitektur?
Svar: Mikroarkitektur og instruktionssætarkitektur (ISA) udgør tilsammen området computerarkitektur.
Spørgsmål: Hvad står ISA for?
A: ISA står for Instruction Set Architecture.
Spørgsmål: Hvad står µarch for? A: µArch står for mikroarkitektur.
Relaterede artikler
Forfatter
AlegsaOnline.com Mikroarkitektur: CPU'ens interne design, kredsløb og funktion Leandro Alegsa
URL: https://da.alegsaonline.com/art/64586
Kilder
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture