Superskalar CPU: Definition og forklaring af instruktionsparallelisme
Superskalar CPU – klar forklaring af instruktionsparallelisme, hvordan flere funktionelle enheder og dispatch forbedrer ydeevne i moderne processorer.
Et superscalar CPU-design gør en form for parallel beregning kaldet Instruction-level parallelism inden for en enkelt CPU, hvilket gør det muligt at udføre mere arbejde ved samme taktfrekvens. Det betyder, at CPU'en kan begynde og udføre mere end én instruktion i løbet af en enkelt taktcyklus ved at køre flere instruktioner samtidig (ofte kaldet instruktionsdisponering) på flere parallelle funktionelle enheder. Hver funktionel enhed er en eksekveringsressource i CPU-kernen, f.eks. en aritmetisk logisk enhed (ALU), en flydende point-enhed (FPU), en bitskifter eller en multiplikator.
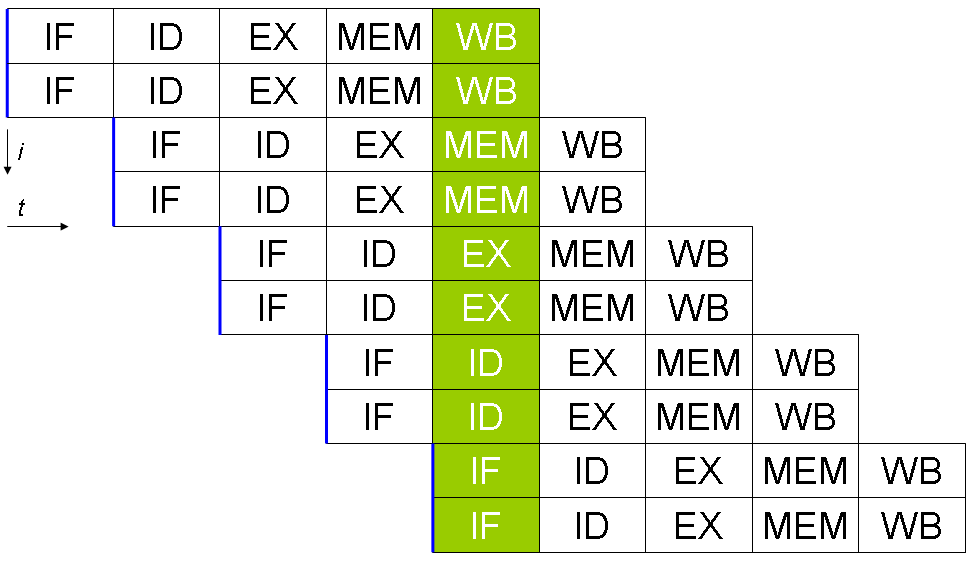
De fleste superskalare CPU'er er også pipelined, men det er teoretisk muligt at have en superskalar CPU uden pipeline eller en ikke-superskalar CPU med pipeline. Kombinationen af pipelining og superskalaritet øger gennemløbet (throughput), fordi flere instruktioner både er i gang samtidigt og på forskellige stadier i eksekveringen.
Billedgalleri
2 Billeder
Hvad kræves i kernen for at understøtte superskalaritet?
Den superskalære teknik afhænger af flere funktioner i CPU-kernen for at fungere effektivt:
- Instruktioner skal hentes i en ordnet instruktionsliste, så kontrolflowet er veldefineret.
- CPU-hardware skal kunne afgøre, hvilke instruktioner der har dataafhængigheder (hvilke instruktioner læser/skrives samme registre eller hukommelsesadresser), så uafhængige instruktioner kan udføres parallelt.
- CPU'en skal kunne læse og afkode flere instruktioner pr. clockcyklus (fetch/decode flere instruktioner samtidig).
Hvordan adskiller superskalar fra skalar og vektor
En skalarprocessor udfører typisk én instruktion, som ændrer ét eller et par dataelementer. En vektorprocessor (eller SIMD) behandler mange dataelementer i én instruktion. En superskalar processor kombinerer principperne:
- Hver instruktion opererer typisk på ét dataelement (skalar):
- Der er flere parallelle funktionelle enheder i hver CPU-kerne, så flere instruktioner, der er uafhængige, kan behandles samtidigt på forskellige dataelementer.
Instruktionsdispensering og orkestrering
I en superskalær CPU læser en instruktionsfordeler (ofte kaldet dispatcher eller issue unit) instruktioner fra hukommelsen, analyserer afhængigheder og beslutter, hvilke instruktioner der sikkert kan køres parallelt. Dispensereren fordeler disse instruktioner til de ledige funktionelle enheder i CPU'en. For at gøre dette effektivt benyttes ofte teknikker som:
- Out-of-order execution — instruktioner kan eksekveres i en anden rækkefølge end den programmerede, så længe det ikke ændrer programmets resultat.
- Register renaming — eliminerer falske afhængigheder (write-after-read og write-after-write) ved at give fysiske registre nye navne.
- Reorder buffer (ROB) — tillader instruktioner at blive committet i den originale rækkefølge, selv om eksekvering skete out-of-order.
- Branch prediction — forudsiger udfaldet af betingede hop for at holde pipeline og funktionelle enheder forsynet med instruktioner.
- Scoreboarding eller Tomasulo-lignende algoritmer — til sporning af afhængigheder og til at koordinere udstedelse til funktionelle enheder.
Begrænsninger og flaskehalse
Superskalaritet øger potentialet for parallelt arbejde, men reelle gevinster er begrænsede af flere faktorer:
- Dataafhængigheder: Instruktioner, der læser efter instruktioner, som skriver de samme data, kan ikke eksekveres i parallel uden specielle teknikker.
- Kontrolafhængigheder: Branches og hop skaber usikkerhed om, hvilke instruktioner der skal hentes næste, hvilket kan føre til afbrydelser ved forkerte branch-predictions.
- Strukturelle konflikter: Hvis to instruktioner konkurrerer om den samme funktionelle enhed, kan kun én køre ad gangen.
- Begrænset ILP: Der er kun et begrænset antal uafhængige instruktioner i et programvindue; derfor når man et punkt med faldende ekstraudbytte, selv om man øger antallet af funktionelle enheder.
- Hukommelseslatency og cache-misses: Lang ventetid på data (f.eks. ved cache-misses) kan tvinge enheden til at vente, medmindre der er nok uafhængigt arbejde at tage over.
Ydelsesmålinger
Typiske mål for hvor effektiv en superskalar CPU er inkluderer:
- Instructions per cycle (IPC): Gennemsnitligt antal instruktioner, der faktisk fuldføres pr. clockcyklus.
- Issue width: Hvor mange instruktioner CPU'en kan udstede pr. cyklus (f.eks. 2‑vejs, 4‑vejs eller 6‑vejs superskalar).
- Brug af funktionelle enheder (utilization) og effekt af branch mispredictions og cache-misses.
Sammenligning med andre tilgange
Superskalaritet forsøger at finde parallellisme på instruktionsniveau i en enkelt tråd. Alternative eller supplerende tilgange er:
- VLIW (Very Long Instruction Word): Kompileringsstyret parallellisme hvor flere operationer eksplicit sættes i én lang instruktion — hardwareen er enklere, men compiler og binærkompatibilitet er udfordringer.
- SIMD / vector-enheder: Behandler mange dataelementer med én instruktion — effektivt for data-parallelle opgaver som multimedia og videnskabelige beregninger.
- Multicore og multithreading: I stedet for at finde parallellisme inden for én tråd, kører flere kerner eller tråde samtidigt; dette øger throughput for mange-programs- eller mange-tråde arbejdsbelastninger.
Praktisk historie og moderne anvendelse
I praksis er de fleste moderne generelle CPU'er superskalære. Arkitekturer fra 1990'erne og frem (Intel, AMD, ARM i avancerede varianter osv.) bruger kombinationer af pipelining, superskalar issue, out-of-order execution, register renaming og branch prediction for at opnå højt IPC. Moderne design kan have fra et par op til flere parallelle ALU'er, flere FP-enheder samt SIMD-enheder; issue width i kommercielle design ligger ofte i intervallet 2–8 instruktioner pr. cyklus afhængig af målarkitektur og strøm/arealkrav.
Design-tradeoffs
At øge superskalariteten (flere issue slots og flere funktionelle enheder) forbedrer potentielt ydelsen, men øger også kompleksiteten, strømforbruget og silikonearealet. Derfor afvejes gevinst i IPC mod omkostninger til strøm, varme, timing og compiler-understøttelse.
Sammenfattende giver superskalar CPU-design en effektiv måde at udnytte parallellisme på instruktionsniveau, men effektiviteten afhænger af både hardwaremekanismer (dispensering, renaming, ROB, branch-prediction, m.v.) og karakteren af de programmer, der køres.


Begrænsninger
Forbedring af ydeevnen i Superscalar CPU-design er begrænset af to ting:
- Niveauet af indbygget parallelisme i instruktionslisten
- Kompleksiteten og tidsforbruget ved dispatcher- og dataafhængighedskontrol.
Selv med uendelig hurtig afhængighedskontrol i en normal superskalær CPU ville det også begrænse den mulige forbedring af ydeevnen, hvis selve instruktionslisten har mange afhængigheder, så mængden af indbygget parallelitet i koden er en anden begrænsning.
Uanset hvor hurtigt dispatcheren er, er der en praktisk grænse for, hvor mange instruktioner der kan sendes samtidigt. Selv om fremskridt inden for hardware vil gøre det muligt at få flere funktionelle enheder (f.eks. ALU'er) pr. CPU-kerne, øges problemet med at kontrollere instruktionsafhængigheder til en sådan grad, at den opnåelige grænse for superskalar dispatching er noget lille. -- Sandsynligvis i størrelsesordenen fem til seks instruktioner, der sendes samtidigt.
Alternativer
- Simultaneous multithreading, ofte forkortet SMT, er en teknik til at forbedre den samlede hastighed for superskalare CPU'er. SMT gør det muligt at udføre flere uafhængige tråde for bedre at udnytte de ressourcer, der er til rådighed i en moderne superskalær processor.
- Multi-core-processorer: Superskalare processorer adskiller sig fra multi-core-processorer ved, at de mange redundante funktionelle enheder ikke er hele processorer. En enkelt superskalær processor består af avancerede funktionelle enheder såsom ALU, heltalsmultiplikator, heltalsskifter, flydepunktsenhed (FPU) osv. Der kan være flere versioner af hver funktionel enhed for at muliggøre parallel udførelse af mange instruktioner. Dette adskiller sig fra en multikerneprocessor, som samtidig behandler instruktioner fra flere tråde, en tråd pr. kerne.
- Pipelined-processorer: Superscalar-processorer adskiller sig også fra en pipelined CPU, hvor flere instruktioner samtidig kan være i forskellige stadier af udførelse.
De forskellige alternative teknikker udelukker ikke hinanden - de kan (og bliver ofte) kombineret i en enkelt processor, så det er muligt at designe en multicore-CPU, hvor hver kerne er en uafhængig processor med flere parallelle superskalare pipelines. Nogle multicore-processorer omfatter også vektorkapacitet.
Relaterede sider
- Parallel databehandling
- Parallelitet på instruktionsniveau
- Simultan multithreading (SMT)
- Multi-core-processorer
Spørgsmål og svar
Spørgsmål: Hvad er superskalarteknologi?
A: Superscalar teknologi er en form for grundlæggende parallel databehandling, der gør det muligt at behandle mere end én instruktion i hver clockcyklus ved at bruge flere eksekveringsenheder på samme tid.
Spørgsmål: Hvordan fungerer superscalar teknologi?
Svar: Superscalar teknologi indebærer, at instruktionerne kommer ind i processoren i rækkefølge, at der kigges efter dataafhængigheder, mens den kører, og at der indlæses mere end én instruktion i hver clockcyklus.
Spørgsmål: Hvad er forskellen mellem skalarprocessorer og vektorprocessorer?
Svar: På en skalar-processor arbejder instruktionerne normalt med et eller to dataelementer på én gang, mens instruktionerne på en vektor-processor normalt arbejder med mange dataelementer på én gang. En superskalær processor er en blanding af begge dele, da hver instruktion behandler ét dataelement, men der kører mere end én instruktion på én gang, så processoren behandler mange dataelementer på én gang.
Spørgsmål: Hvilken rolle spiller en præcis instruktionsfordeler i en superskalær processor?
Svar: En nøjagtig instruktionsfordeler er meget vigtig for en superskalær processor, da den sikrer, at eksekveringsenhederne altid er optaget af det arbejde, der sandsynligvis vil være nødvendigt. Hvis instruktionsfordeleren ikke er nøjagtig, kan det være, at noget af arbejdet skal smides væk, hvilket ville gøre den ikke hurtigere end en scaler-processor.
Spørgsmål: I hvilket år blev alle normale CPU'er superskalære?
Svar: Alle normale CPU'er blev superscalere i 2008.
Spørgsmål: Hvor mange ALU'er, FPU'er og SIMD-enheder kan der være på en normal CPU?
Svar: På en normal CPU kan der være op til 4 ALU'er, 2 FPU'er og 2 SIMD-enheder.
Relaterede artikler
Forfatter
AlegsaOnline.com Superskalar CPU: Definition og forklaring af instruktionsparallelisme Leandro Alegsa
URL: https://da.alegsaonline.com/art/95080