Zipfs lov: Definition og forklaring af ordhyppighed og rangfordelinger
Zipfs lov forklaret: Hvad ordhyppighed og rangfordelinger betyder, hvorfor 1/n-mønsteret opstår, og hvordan det påvirker sprog, byer og økonomi.
Zipfs lov er en empirisk lov, der er formuleret ved hjælp af matematisk statistik og er opkaldt efter lingvisten George Kingsley Zipf, som først foreslog den. Zipfs lov beskriver den typiske sammenhæng mellem et elements rang i en hyppigheds- eller størrelsesrangliste og dets forekomst eller størrelse.
Definition: Zipf's lov siger, at når man tager en stor stikprøve af anvendte ord, er hyppigheden af et ord omvendt proportional med dets placering i hyppighedstabellen. Ord nummer n har altså en frekvens, der er proportional med 1/n. Mere generelt kan man skrive den som
f(r) ∝ 1 / r^s
hvor f(r) er frekvensen af elementet med rang r, og s er en eksponent, der ofte ligger tæt på 1 for sprogdata (Zipfs oprindelige form svarer til s = 1). For en endelig samling af N elementer kan man normalisere ved hjælp af den harmoniske sum H_{N,s} så f(r) = (1 / r^s) / H_{N,s}.
Billedgalleri
3 Billeder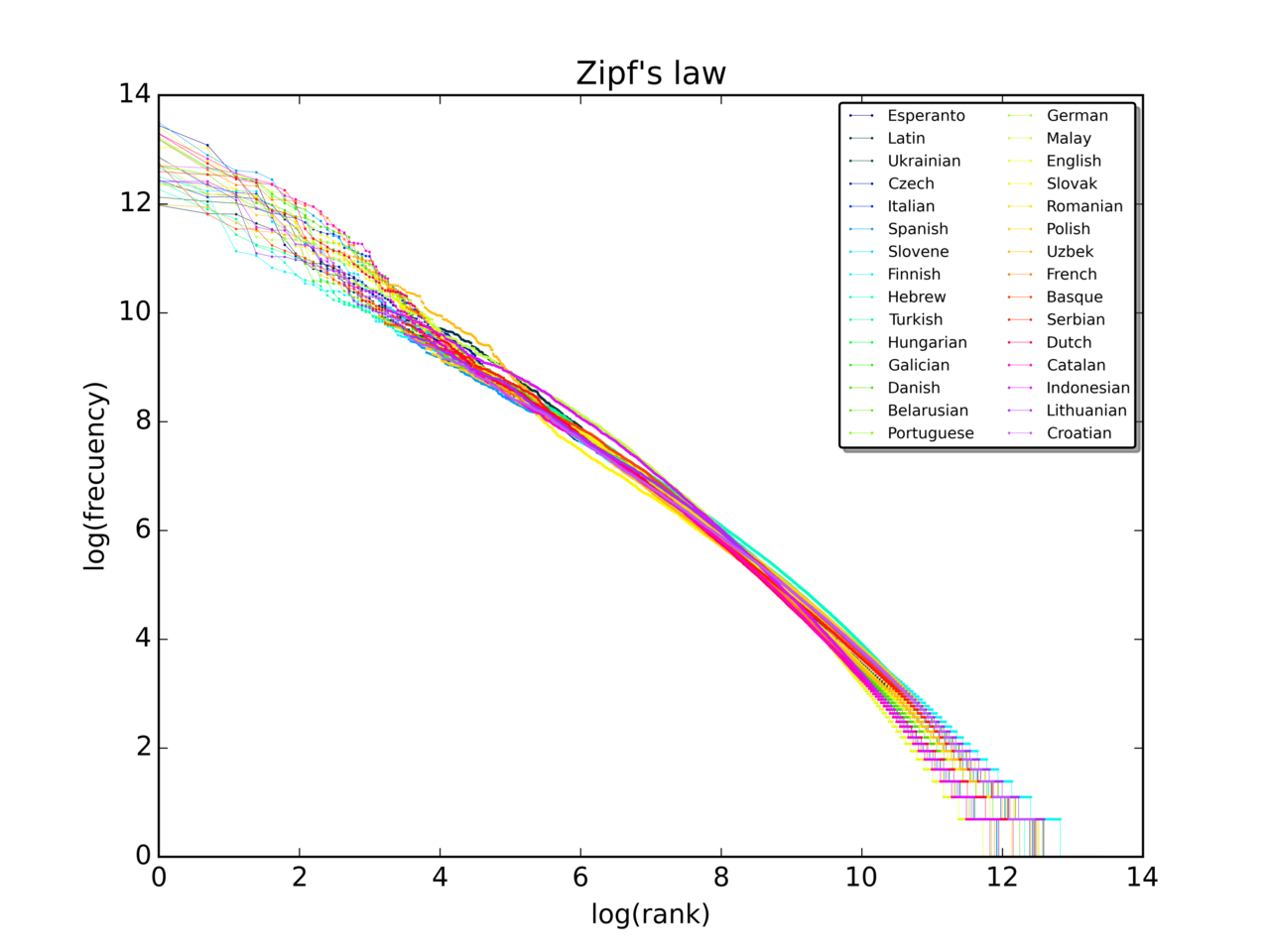


Eksempler
Det mest hyppige ord vil således forekomme ca. dobbelt så ofte som det næsthyppigste ord, tre gange så ofte som det tredjehyppigste ord osv. I en stikprøve af ord i det engelske sprog udgør det hyppigst forekommende ord, "the", f.eks. næsten 7 % af alle ord (69 971 ud af lidt over 1 million). I overensstemmelse med Zipfs lov udgør det næstmest hyppige ord "of" lidt over 3,5 % af alle ord (36 411 forekomster), efterfulgt af "and" (28 852). Der skal kun ca. 135 ord til for at udgøre halvdelen af alle ord i en stor stikprøve.
Det samme forhold gør sig gældende i mange andre ranglister, som ikke har noget med sprog at gøre, f.eks. befolkningsrækkefølgen for byer i forskellige lande, virksomhedsstørrelser, indkomstrækkefølger osv. Felix Auerbach bemærkede for første gang i 1913, at fordelingen i ranglisterne over byer efter befolkningstal følger en lignende rangfordeling (senere kaldet Zipf-lignende fordeling).
Matematisk og statistisk kontekst
Zipfs lov er et særligt tilfælde af en såkaldt potensfordeling (power law). Når s = 1, er rang-frekvens-relationen f(r) ∝ 1/r. Hvis man i stedet betragter størrelserne x som tilfældigt fordelte, svarer en rang-afledt Zipf-fordeling ofte til en størrelse-fordeling med en hale, der falder som p(x) ∝ x^{-α}. Forbindelsen mellem eksponenterne er sådan, at α = 1 + 1/s (hvilket giver α ≈ 2 når s ≈ 1).
Ved empirisk estimering af eksponenten anvendes typisk log-log-plot (hvor fordelingen fremstår som en tilnærmet ret linje), men moderne metoder foretrækker maksimum-likelihood-estimater og goodness-of-fit-test (f.eks. Kolmogorov–Smirnov-test) for at vurdere, hvor godt en potensmodel passer til dataene.
Mulige forklaringer og modeller
- Kommunikationens økonomi (Zipfs egen idé): Zipf argumenterede for et kompromis mellem talerens ønske om at minimere indsats (have få ord) og lytterens ønske om klarhed (have mange ord), hvilket kan føre til en rangfordeling med kraftigt skævt forbrug.
- Preferentiel tilknytning og Simon-modellen: Stokastiske modeller hvor allerede hyppige elementer har større sandsynlighed for at blive brugt igen (”the rich get richer”) kan generere fordelinger tæt på Zipfs lov.
- Mandelbrots modifikation: Benoît Mandelbrot foreslog en generaliseret form f(r) ∝ 1/(r + q)^s som ofte passer bedre i praksis især for lave rangnumre (hvor r+q regulariserer kurven).
Anvendelser og begrænsninger
Zipfs lov bruges til at beskrive og modellere sprog, bystørrelser, webtrafik, firmastørrelser, visse biologiske variable og flere socioøkonomiske fænomener. Dog optræder afvigelser:
- I meget små korpora eller korte tekster passer Zipfs lov ofte dårligt.
- Sprog med kompleks morfologi (fx agglutinerende sprog) kan vise andre rank-fordelinger for ordformer, fordi et enkelt leksikalsk ord kan skabe mange bøjningsformer.
- Afvigelser ses ofte i toppen (de mest hyppige få ord) og i halen (særligt sjældne ord), hvor andre funktioner eller cutoff-værdier kan være nødvendige for præcis modellering.
Relation til andre fordelinger
Zipfs lov er tæt forbundet med Pareto- og kraftlovsfordelinger. Hvor Zipf beskriver rang versus frekvens, beskriver Pareto ofte størrelse versus andel; begge rammer fanger den grundlæggende egenskab ved ’tunge haler’ og stor varians mellem elementerne i en population.
Det vides ikke fuldt ud, hvorfor Zipfs lov gælder så bredt i sprog og andre domæner; der er flere komplementære forklaringer (økonomisk effektivitet, stochastiske vækstprocesser, kognitive og sociale mekanismer), og emnet er stadig aktivt forskningsområde.
Praktisk pointer: Når man møder en rangfordeling i data, er det nyttigt at undersøge, om en Zipf- eller generel potensmodel kan beskrive mønstret — men man bør altid teste modelpasset statistisk og overveje alternative forklaringer og dataspecifikke forhold.
Spørgsmål og svar
Q: Hvad er Zipfs lov?
A: Zipfs lov er en empirisk lov, der siger, at hyppigheden af et ord i en stor stikprøve er omvendt proportional med dets rang i hyppighedstabellen.
Q: Hvem foreslog Zipfs lov?
A: Zipfs lov blev først foreslået af George Kingsley Zipf, en lingvist.
Q: Hvordan forklarer Zipfs lov ordfrekvensen i en stikprøve af engelske ord?
A: Ifølge Zipfs lov forekommer det hyppigste ord i en stikprøve af engelske ord ca. dobbelt så ofte som det næsthyppigste ord, tre gange så ofte som det tredjehyppigste ord osv. Denne tendens fortsætter, når ordets rang falder.
Q: Hvor mange procent af alle ord udgør det hyppigst forekommende ord i en stikprøve af engelske ord?
A: I en stikprøve af engelske ord udgør det hyppigst forekommende ord ("the") næsten 7% af alle ordene.
Spørgsmål: Hvad er forholdet mellem det antal ord, der skal til for at udgøre halvdelen af stikprøven, og hyppigheden af disse ord?
A: Ifølge Zipfs lov er der kun brug for ca. 135 ord for at gøre rede for halvdelen af ordene i en stor stikprøve.
Spørgsmål: Hvilke andre rangordninger udviser Zipfs lov?
A: Det samme forhold, som Zipfs lov beskriver i hyppigheden af ord, forekommer i andre rangordninger, der ikke har noget med sprog at gøre, såsom rangordningen af byer i forskellige lande, virksomhedsstørrelser og indkomstrangordninger.
Q: Hvem lagde mærke til fordelingen i rangeringen af byer efter indbyggertal?
A: Fordelingen i rangordningen af byer efter indbyggertal blev først bemærket af Felix Auerbach i 1913.
Relaterede artikler
Forfatter
AlegsaOnline.com Zipfs lov: Definition og forklaring af ordhyppighed og rangfordelinger Leandro Alegsa
URL: https://da.alegsaonline.com/art/110649
Kilder
- books.google.com : P. 139