Cache-algoritmer — guide og forklaring (LRU, LFU, ARC)
Guide til cache-algoritmer (LRU, LFU, ARC): forstå hitrate, latency, fordele og implementeringer — vælg den bedste strategi for hurtigere og mere effektiv caching.
En cache-algoritme er en algoritme, der bruges til at administrere en cache eller en gruppe af data. Når cachen er fuld, vælger algoritmen hvilket element der skal fjernes for at give plads til nye elementer. Ordet hitrate beskriver, hvor ofte en forespørgsel kan betjenes fra cachen. Udtrykket latency beskriver, hvor lang tid det tager at hente et element fra cachen eller fra den underliggende lagerenhed. Cache-algoritmer balancerer typisk mellem ønsket om høj hitrate og lav latenstid, men valg af algoritme afhænger af arbejdsbelastningens karakteristika (f.eks. temporal lokalitet og adgangsfrekvenser).
Billedgalleri
7 Billeder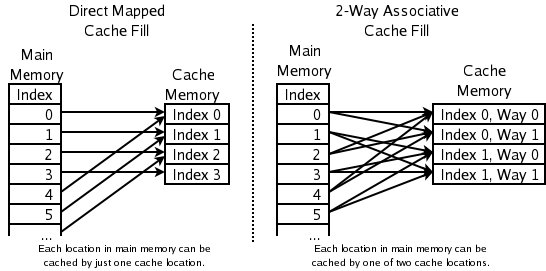



Det teoretiske optimum og Belady
Det teoretisk bedste valg er altid at kassere de data, som ikke vil blive brugt i længst tid frem i tiden — det giver den maksimale hitrate. Dette optimale resultat kaldes Belady's optimale algoritme eller den clairvoyante algoritme, fordi den kræver fuld viden om alle fremtidige forespørgsler. I praksis er denne information ikke tilgængelig, så Belady bruges primært som et teoretisk minimum til at måle, hvor tæt en reel algoritme kommer på optimal ydelse.
Typiske politikker og deres egenskaber
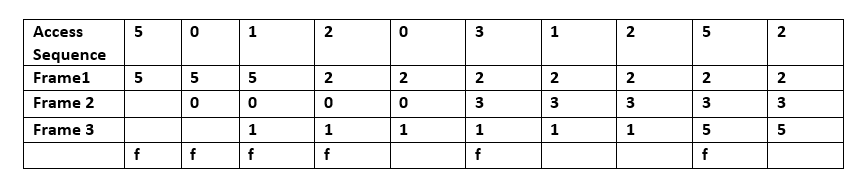
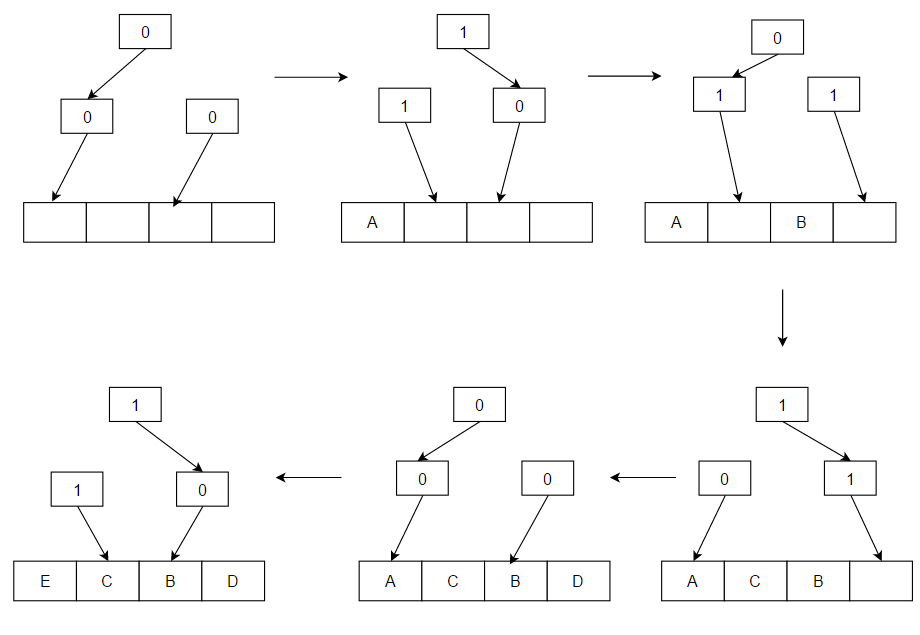
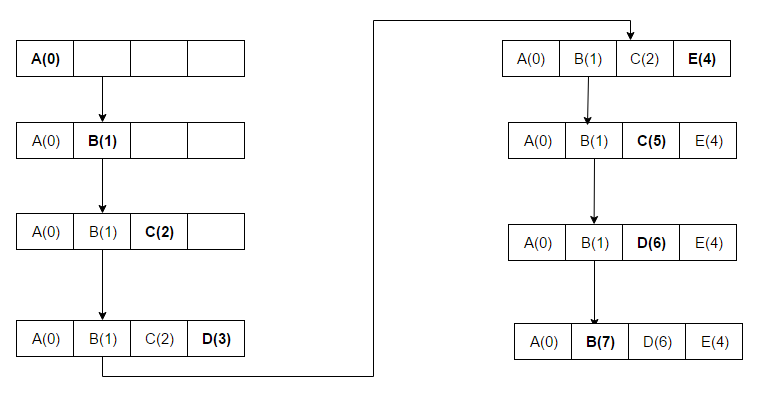
- Least Recently Used (LRU): Sletter de mindst nyligt anvendte elementer først. LRU antager temporal lokalitet — at nyligt brugte elementer sandsynligvis bliver brugt igen. Praktiske implementeringer bruger ofte en dobbeltkædet liste sammen med et hashtabel for at opnå O(1)-indsættelse, adgang og fjernelse. LRU findes i mange varianter (se nedenfor) og fungerer godt for workloads med stærk temporal lokalitet.
- Most Recently Used (MRU): Fjerner de senest anvendte elementer først. MRU kan være nyttig i situationer hvor den seneste adgang betyder, at elementet ikke vil blive genbrugt (f.eks. visse database-workloads eller når adgangssekvenser bevæger sig gennem store datasæt).
- Pseudo-LRU (PLRU): En plads- og beregningsvenlig approximation af LRU, ofte brugt i CPU-cacher. I stedet for at spore fuld rækkefølge, ved PLRU typisk med få bits (fx træ-baseret eller clock-bit) hvilke linjer der er mindst sandsynligt at blive genbrugt. PLRU giver lav overhead men kan nogle gange vælge et suboptimalt offer sammenlignet med fuld LRU.
- Least Frequently Used (LFU): Tæller hvor ofte hvert element bruges og fjerner de mindst hyppigt brugte. LFU fanger frekvenslokalitet (objekter der bruges ofte over længere tid), men kan være langsomt til at reagere på ændringer i adgangsvolatilitet uden yderligere mekanismer (f.eks. aging eller decay af tællere).
- Adaptive Replacement Cache (ARC): Kombinerer fordelen ved LRU og LFU ved at justere en intern balanceparameter dynamisk ud fra workloaden. ARC kan give bedre samlet ydelse, fordi den tilpasser sig ændringer i både frekvens og recency.
Varianter og praktiske implementeringer
- LRU-familien: LRU er ikke én enkelt metode, men en familie af teknikker. Nogle kendte varianter er 2Q (Theodore Johnson & Dennis Shasha) og LRU/K (Pat O'Neil m.fl.), som forsøger at skille kortsigtede tilfældige referencer fra genbrugte objekter for bedre ydelse. Du finder disse nævnt som eksempler på avancerede LRU-baserede tilgange: en familie af caching-algoritmer med bl.
- Clock-algoritme: En effektiv PLRU-lignende algoritme, der bruger en cirkulær buffer og en brugt-bit (reference-bit). Når et offer skal findes, scansringes bufferet, og reference-bits bruges til at give "et ekstra liv" til nyligt brugte poster. Enkel og billig i hardware og software.
- 2-vejs sæt-associativ: Typisk i CPU-cacher hvor ydeevne er kritisk. Et nyt element kan kun placeres i to forudbestemte linjer (et par); den LRU af de to kasseres. Denne løsning kræver kun én bit pr. par for at angive den mindst brugte linje, hvilket er hurtigere end fuld LRU.
- Direct-mapped cache: Den hurtigste og simpleste metode: hver adresse mappes til én enkelt cacheplacering. Det som lå der før, kasseres. Kraftig konfliktfølsomhed, men minimal hardware/overhead og lav latenstid.
- Greedy-Dual-Size og varianter: Når elementer har forskellig størrelse eller forskellige omkostninger ved at hente dem, bruges ofte en værdi-baseret strategi (fx cost/size) til at prioritere hvad der skal bevares.
- Andre avancerede algoritmer: 2Q, LRU/K, Multi Queue (MQ — Y. Zhou, J.F. Philbin og Kai Li) og andre hybridmetoder forsøger at kombinere fordele fra LRU og LFU og håndtere praktiske problemer som bursty adfærd og skiftende arbejdsbelastninger.
Praktiske overvejelser ved valg af algoritme
- Arbejdsbelastning: Forstå mønstrene: har du stærk temporal lokalitet (LRU-venligt) eller langtidsholdte populære objekter (LFU-venligt)? Hybridløsninger (ARC, MQ) er ofte gode hvis mønstrene skifter.
- Omkostninger ved hentning: Behold objekter, som er dyre at hente (netværk, disk), selvom de ikke er de hyppigst tilgåede.
- Forskellig størrelse af objekter: Når elementer har varierende størrelse, kan en simpel tælling per element føre til lav effektivitet. Algoritmer som Greedy-Dual-Size tager størrelse med i beslutningen.
- Udløb (TTL): Nogle caches har tidsbegrænsede poster (f.eks. DNS, webcache). Hvis mange poster udløber, kan simpel TTL-håndtering være nok til at holde cachen frisk uden komplekse bortskafningsregler.
- Skrivepolitik: Overvej write-through vs. write-back for caches der håndterer opdateringer — det påvirker konsistens, latenstid og kompleksitet.
- Måling og tuning: Mål hitrate, miss-rate, og latenstid under repræsentative arbejdsbelastninger. Varm cachen op før måling (warm-up) og anvend belastningsprofiler der svarer til produktion.
Cache-konsistens og distribuerede scenarier
Når flere uafhængige caches arbejder på de samme data (fx flere databaseinstanser eller distribuerede webcaches), opstår behovet for mekanismer til at sikre, at kopier ikke bliver inkonsistente. Der findes forskellige tilgange til at opretholde cache-kohærens, såsom invalidering, skrive-broadcast, lease-baserede systemer og konsistensprotokoller designet til den konkrete applikation og krav til latenstid og holdbarhed.
Anbefalinger i praksis
- Start med LRU hvis dine forespørgsler viser stærk recency (typisk browsercaches, mange applikationer).
- Brug ARC eller MQ hvis dine adgangsmønstre både indeholder hyppige populære objekter og kortsigtede hot spots.
- Vælg PLRU/clock eller direkte mapping for meget performance-kritiske caches (fx CPU-cache) hvor overhead skal minimeres.
- Tag højde for objektstørrelse og fetch-omkostninger — brug cost-aware strategier hvis nødvendigt.
- Mål og evaluer: sammenlign med Belady's grænse (hvor muligt) eller simulér arbejdslasten for at vurdere forbedringer.
Til sidst er det vigtigt at huske, at den bedste cache-algoritme afhænger af den konkrete anvendelse, adgangsmønstre og hardwarebegrænsninger. Kombinationer og adaptive metoder giver ofte de mest robuste resultater i virkelige systemer.

Spørgsmål og svar
Spørgsmål: Hvad er en Cache-algoritme?
A: En Cache-algoritme er en algoritme, der bruges til at administrere en cache eller en gruppe af data. Den bestemmer, hvilket element der skal slettes fra cachen, når den er fuld.
Spørgsmål: Hvad er hit rate?
A: Hit rate beskriver, hvor ofte en anmodning kan betjenes fra cachen.
Spørgsmål: Hvad beskriver latenstid?
Svar: Latency beskriver, hvor længe et element i cachen kan hentes.
Spørgsmål: Hvad er Belady's optimale algoritme?
Svar: Beladys optimale algoritme, også kendt som den clairvoyante algoritme, er en effektiv caching-algoritme, som altid kasserer de oplysninger, der ikke vil blive brugt i længst tid fremover. Dette resultat kan generelt ikke gennemføres i praksis, fordi det kræver, at man kan forudsige, hvad der vil blive brug for langt ude i fremtiden.
Spørgsmål: Hvordan fungerer LRU (Least Recently Used)?
Svar: LRU sletter de elementer, der er brugt mindst for nylig, først og kræver, at man holder styr på, hvad der blev brugt hvornår, ved at bruge "aldersbits" for hver cache-linje og spore, hvilken linje der blev brugt mindst for nylig på grundlag af aldersbits. Hver gang en cache-linje bruges, ændres alle andre cache-linjers alder tilsvarende.
Spørgsmål: Hvordan fungerer MRU (Most Recently Recently Used)?
Svar: MRU sletter de senest anvendte elementer først, og denne cachingmekanisme anvendes almindeligvis til databasehukommelsescaches.
Spørgsmål: Hvilke andre algoritmer findes der til at opretholde cachekohærens?
Svar: Der findes forskellige algoritmer til at opretholde cachekohærens, når flere uafhængige caches anvendes til delte data, f.eks. flere databaseservere, der opdaterer en enkelt delt datafil.
Relaterede artikler
Forfatter
AlegsaOnline.com Cache-algoritmer — guide og forklaring (LRU, LFU, ARC) Leandro Alegsa
URL: https://da.alegsaonline.com/art/15882
Kilder
- usenix.org : usenix.org/legacy/events/fast03/tech/full_papers/megiddo/megiddo.pdf
- usenix.org : usenix.org